

Analisis diskriminan adalah teknik statistik multivariat yang digunakan untuk menguji apakah suatu kelompok individu dapat diklasifikasikan berdasarkan variabel-variabel independen tertentu. Tujuan dari analisis diskriminan adalah untuk membedakan kelompok-kelompok berdasarkan variabel-variabel independen yang dipilih.
Analisis diskriminan memerlukan adanya satu variabel dependen (kelompok-kelompok) dan satu atau lebih variabel independen (pengukuran-pengukuran). Dalam analisis diskriminan, kita mencari perbedaan signifikan antara kelompok-kelompok dalam variabel independen. Dengan menggunakan informasi ini, kita dapat mengklasifikasikan individu baru ke dalam kelompok-kelompok yang ada.
Sebelum melakukan analisis diskriminan, ada beberapa asumsi yang harus dipenuhi, yaitu:
- Variabel bebas berdistribusi normal.
- Memiliki varians kovarians sama untuk semua variabel bebas.
- Tidak terjadi multikolinearitas antar variabel bebas.
- Tidak terdapat data ekstrem (outlier).
Persamaan analisis diskriminan:
Yjk = a1X1k + a2X2k + … + anXnk
Keterangan:
Yjk = skor diskriminan j untuk objek k yang kemudian di dummy kan
aj = penimbang diskriminan untuk variabel independen i
Xjk = Variabel pembeda i untuk objek k
Skor diskriminan tersebut digunakan untuk menentukan objek ke-k masuk ke dalam kelompok yang mana. Apabila data dapat dikelompokkan dengan benar 100%, maka model diskriminan sudah bagus (namun biasanya terdapat error / kesalahan pengelompokkan).
Aturan pengelompokkan pada analisis diskriminan:
- Cutting Score
Misalkan kita ingin mengklasifikasikan objek ke dalam 2 kelompok:
- Observasi masuk ke dalam kelompok 1 jika:
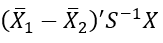
mendekati
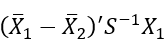
- Observasi masuk ke dalam kelompok 2 jika:
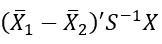
mendekati
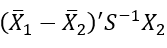
2. Prior Probability (untuk meminimumkan misklasifikasi).
Prior Probability adalah peluang suatu observasi masuk dalam suatu kelompok tanpa adanya pengetahuan mengenai nilai x.
3. Meminimumkan biaya misklasifikasi.
Misklasifikasi untuk menilai apakah pengklasifikasian yang dilakukan sudah tepat atau belum, maka dilakukan penghitungan misklasifikasi.
- Total Probability Misclassification (TPM):
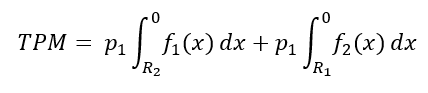
Semakin kecil nilai TPM dan biaya misklasifikasi, maka semakin bagus.
- Statistik APER (Apparent Error Rate) adalah ukuran untuk menghitung seberapa besar akan terjadi misklasifikasi. APER bisa dihitung dari matriks confusion.
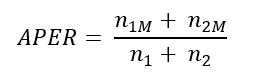
Misal: didapat nilai APER sebesar 20% yang artinya ketidakpastian klasifikasi adalah sebesar 20%. Sementara klasifikasi (HIT RATIO) adalah sebesar 80%.
4. Jarak Mahalanobis (Mahalanobis Distant).
Contoh Soal:

2. Sebuah perusahaan ingin mengetahui faktor-faktor apa saja yang mempengaruhi keberhasilan karyawan dalam mendapatkan promosi. Perusahaan tersebut mengumpulkan data dari 100 karyawan yang mendapatkan promosi, termasuk usia, lama bekerja, jenis kelamin (1 untuk laki-laki, 2 untuk perempuan), dan pendidikan (1 untuk S1, 2 untuk S2). Gunakan analisis diskriminan untuk menentukan faktor-faktor yang paling mempengaruhi keberhasilan karyawan dalam mendapatkan promosi.
| Usia | Lama Bekerja | Jenis Kelamin | Pendidikan |
| 25 | 2 | Laki-Laki | S1 |
| 27 | 4 | Laki-Laki | S1 |
| 30 | 6 | Laki-Laki | S1 |
| 32 | 8 | Laki-Laki | S1 |
| 28 | 4 | Perempuan | S2 |
| 31 | 5 | Perempuan | S2 |
| 33 | 7 | Perempuan | S2 |
| 29 | 3 | Perempuan | S2 |
| 26 | 1 | Perempuan | S2 |
| 24 | 3 | Laki-Laki | S1 |
| 23 | 1 | Laki-Laki | S1 |
| 25 | 3 | Laki-Laki | S1 |
| 26 | 4 | Perempuan | S2 |
| 29 | 6 | Perempuan | S2 |
| 31 | 8 | Perempuan | S2 |
| 32 | 10 | Perempuan | S2 |
| 30 | 7 | Perempuan | S2 |
| 27 | 5 | Laki-Laki | S1 |
| 28 | 6 | Laki-Laki | S1 |
| 33 | 8 | Laki-Laki | S1 |
Jawab:
Berikut ini adalah syntax R untuk melakukan analisis diskriminan pada data tersebut:
# Memuat package yang dibutuhkan
library(MASS)
# Membuat dataset
data <- data.frame(
usia = c(25, 27, 30, 32, 28, 31, 33, 29, 26, 24, 23, 25, 26, 29, 31, 32, 30, 27, 28, 33),
lama_bekerja = c(2, 4, 6, 8, 4, 5, 7, 3, 1, 3, 1, 3, 4, 6, 8, 10, 7, 5, 6, 8),
jenis_kelamin = c(1, 1, 1, 1, 2, 2, 2, 2, 2, 1, 1, 1, 2, 2, 2, 2, 2, 1, 1, 1),
pendidikan = c(1, 1, 1, 1, 2, 2, 2, 2, 2, 1, 1, 1, 2, 2, 2, 2, 2, 1, 1, 1)
)
# Memeriksa struktur dataset
str(data)
# Menghitung analisis diskriminan
ad <- lda(jenis_kelamin ~ usia + lama_bekerja + pendidikan, data)
# Melihat summary output analisis diskriminan
summary(ad)
Output:
lda(group ~ x1 + x2 + x3, data = data)
Prior probabilities of groups:
0 1
0.500 0.500
Group means:
x1 x2 x3
0 0.170 0.616 0.542
1 0.788 0.358 0.274
Coefficients of linear discriminants:
LD1
x1 -11.8435536
x2 4.4584234
x3 6.9007326
Proportion of trace:
LD1
1.0000
Classification results:
Predicted group
True 0 1
0 10 2
- 3 5
- Prior Probabilities of group: Probabilitas awal dari setiap kelompok. Dalam contoh, nilai prior untuk kedua kelompok adalah 0,5 yang menunjukkan bahwa prioritas untuk setiap kelompok adalah sama.
- Group means: Rata-rata dari setiap variabel predioktor untuk setiap kelompok.
- Coefficients of linear discriminants: Koefisien untuk variabel predictor dari setiap diskriminan. Diskriminan pertama adalah yang paling penting, diikuti yang kedua, dan seterusnya. Koefisien ini menunjukkan seberapa besar kontribusi setiap variabel predictor terhadap pemisahan antara kelompok.
- Proportion of force: Proporsi variabilitas dalam data yang dapat dijelaskan oleh diskriminan. Semakin besar proporsi ini, semakin baik diskriminan dalam membedakan antara kelompok. Dalam contoh di atas, diskriminan pertama mampu menjelaskan 100% variabilitas dalam data.
- Classification results: Hasil klasifikasi yang diperoleh dari analisis diskriminan. Ini menunjukkan seberapa akurat model dalam memprediksi kelompok dari data baru. Dalam contoh di atas, model memiliki akurasi klasifikasi sebesar 85%, yang berarti model mampu memprediksi kelompok dengan benar pada 17 dari 20 kasus.
Karena Koefisien diskriminan menunjukkan bahwa faktor x1 (tingkat pendidikan) memiliki pengaruh yang paling signifikan dalam membedakan kelompok karyawan yang berhasil mendapatkan promosi dan yang tidak berhasil mendapatkan promosi. Dalam memprediksi kelompok karyawan yang berhasil mendapatkan promosi dan yang tidak berhasil mendapatkan promosi, model memiliki akurasi sebesar 85% (17 dari 20 kasus).
Berdasarkan kesimpulan tersebut, dapat disimpulkan bahwa tingkat pendidikan merupakan faktor yang paling memengaruhi keberhasilan karyawan dalam mendapatkan promosi. Oleh karena itu, perusahaan dapat mempertimbangkan faktor ini dalam menentukan kebijakan promosi karyawan di masa depan.
Referensi:
https://www.rumusstatistik.com/2015/03/analisis-diskriminan-discriminant.html
http://a-research.upi.edu/operator/upload/s_mat_0607204_chapter3.pdf
Hair, J. F., Black, W. C., Babin, B. J., & Anderson, R. E. (2019). Multivariate Data Analysis (8th ed.). Cengage Learning.