

Gambar 1 Bayesian dalam Machine Learning
1. Bagaimana konsep Bayesian diterapkan dalam Machine Learning?
Bayesian Machine Learning menggunakan Teorema Bayes untuk memperbarui probabilitas suatu hipotesis berdasarkan bukti baru. Ini berarti model bisa menggabungkan pengetahuan sebelumnya (prior) dan data baru (likelihood) untuk mendapatkan probabilitas terkini (posterior). Bayesian memungkinkan pembelajaran lebih fleksibel dan probabilistik, cocok untuk klasifikasi, inferensi, dan deteksi anomali (Murphy, 2012).
Dalam Machine Learning, Bayesian dipakai untuk memodelkan ketidakpastian dan mengelola probabilitas kondisi dari hipotesis. Contohnya adalah Bayesian Networks yang memodelkan keterkaitan probabilistik antar variabel dengan graf berarah. Bayes Theorem dipakai dalam klasifikasi untuk menghitung probabilitas data masuk ke suatu kelas tertentu, seperti mengenali email spam. Dan inferensi Bayesian digunakan untuk menghitung probabilitas posterior hipotesis menggunakan Teorema Bayes dengan mempertimbangkan probabilitas sebelum kemungkinan terbukti (Barber, 2012).
2. Naïve Bayes Classifier
Naïve Bayes adalah algoritma klasifikasi Machine Learning yang memprediksi kategori suatu titik data menggunakan probabilitas. Algoritma ini mengasumsikan bahwa semua fitur saling independen. Naive Bayes bekerja dengan baik dalam banyak aplikasi dunia nyata, seperti penyaringan spam, klasifikasi dokumen, dan analisis sentimen (Alfi Sabrani dkk, 2020).

Gambar 2 Contoh Klasifikasi Naïve Bayes
Berdasarkan Gambar 2 diketahui bahwa data awal memiliki dua kelas, yaitu lingkarang hijau (y = 1) dan kotak merah (y = 2).

Gambar 3 Estimasi Dimensi Pertama
Adapun pada Gambar 3, distribusi estimasi probabilitas dalam dimensi pertama adalah ![]() .
.
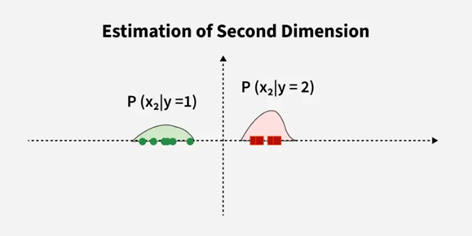
Gambar 4 Estimasi Dimensi Kedua
Dengan distribusi estimasi probabilitas dalam dua dimensi pada Gambar 4 adalah ![]() .
.

Gambar 5 Hasil Distribusi Data
Pada Gambar 5, kedua dimensi digabungkan dengan menggunakan conditional independence (kemandirian bersyarat), sehingga menghasilkan ![]() .
.
3. Bayesian Linear Regression vs. Neural Networks
Regresi dalam konteks Bayesian adalah pendekatan statistik dimana parameter model regresi diperlakukan sebagai variabel acak dengan distribusi probabilitas. Alih-alih mencari satu titik estimasi parameter, Bayesian regression menggabungkan pengetahuan sebelumnya (prior) dengan data yang diperoleh (likelihood) untuk mendapatkan distribusi posterior parameter yang mencerminkan ketidakpastian. Ini memungkinkan analisis lebih kaya dan prediksi dengan interval kepercayaan probabilistik.
Bayesian Linear Regression sederhana mengasumsikan hubungan linear antara variabel. Model ini mudah diinterpretasikan, cepat latih, dan efektif untuk dataset kecil sampai sedang. Sedangkan Neural Network lebih kompleks dan mampu menangkap pola non-linear dan kompleks dalam data melalui banyak lapisan dan parameter. Namun mereka butuh data yang lebih banyak dan waktu pelatihan lebih lama, serta sulit untuk interpretasi.
Model: Model regresi linear Bayesian menyatakan hubungan linear antara variabel output ![]() dan input
dan input ![]() dengan parameter
dengan parameter ![]() (koefisien) dan noise
(koefisien) dan noise ![]() :
:

Prior: Sebelum melihat data, diyakini bahwa parameter ![]() berasal dari distribusi probabilitas tertentu, biasanya distribusi normal Gaussian:
berasal dari distribusi probabilitas tertentu, biasanya distribusi normal Gaussian:

Likelihood: Menggambarkan probabilitas data ![]() diberikan parameter
diberikan parameter ![]() , biasanya diasumsikan Gaussian:
, biasanya diasumsikan Gaussian:
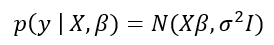
Posterior: Setelah mengamati data, distribusi posterior parameter ![]() diperoleh dengan menggunakan Teorema Bayes:
diperoleh dengan menggunakan Teorema Bayes:

Posterior ini adalah distribusi yang menggabungkan informasi prior dan data observasi, biasanya juga Gaussian dengan mean dan varians baru yang diperbarui.
4. Penerapan dalam klasifikasi teks dan deteksi spam
Naïve Bayes digunakan dalam pengklasifikasian teks seperti filter spam email dengan menghitung probabilitas kata-kata muncul dalam email spam atau bukan. Algoritma ini sederhana, cepat, dan efektif menangani teks berukuran besar untuk klasifikasi real-time.
5. Implementasi Naïve Bayes dalam R Studio
a. Persiapan dan Load Library
Hal pertama yang perlu dilakukan ialah load library yang diperlukan, dimana umumnya menggunakan package e1071 dan caret. Adapun untuk visualisasinya dapat menggunakan package klaR:

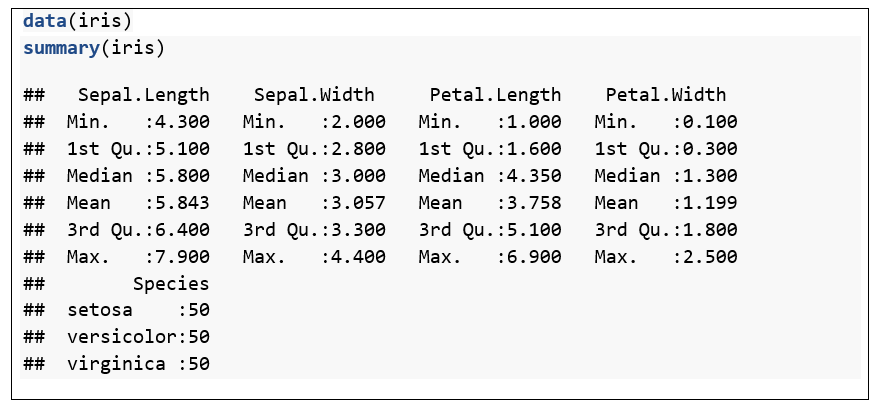
b. Load Data
Data dapat di-input dengan berbagai format, seperti CSV atau Excel. Digunakan data bawaan dari R Studio sebagai contoh, yakni data iris:
c. Naive Bayes Classifier
Lakukan klasifikasi dengan fungsi naiveBayes() dari package e1071:

d. Pemodelan Naive Bayes
Dilakukan pemodelan dengan menggunakan library(caret), dimana data dapat ditampilkan seperti cara awal atau dengan menggunakan perintah names untuk menunjukkan nama kolom:

e. Prediksi dengan Model
Gunakan fungsi predict() untuk memperoleh nilai prediksi dan kelas hasilnya:




f. Visualisasi
Untuk mengetahui berapa banyak kesalahan yang diklasifikasikan maka hasil prediksinya perlu dibandingkan dengan kelas/spesies iris:

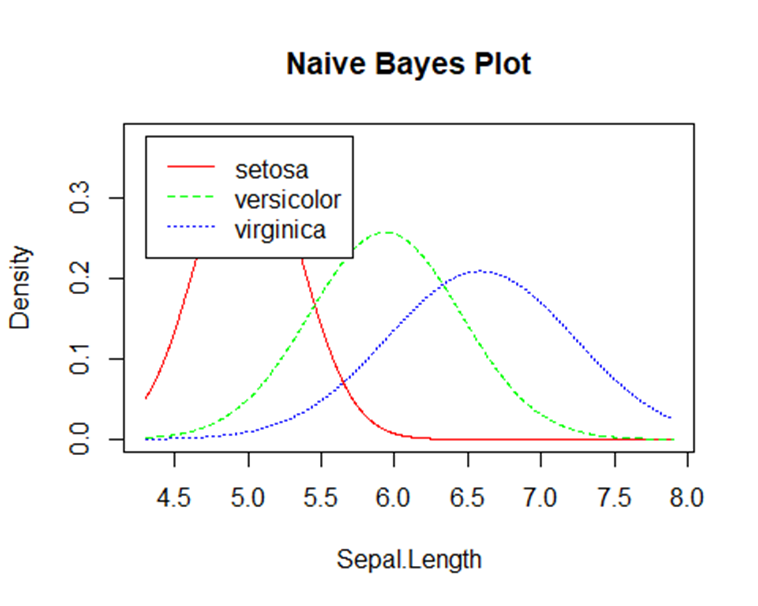

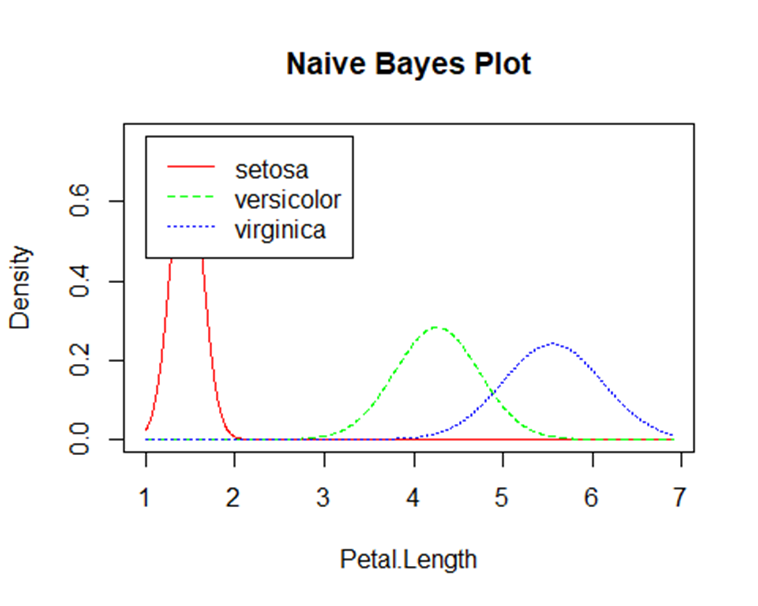
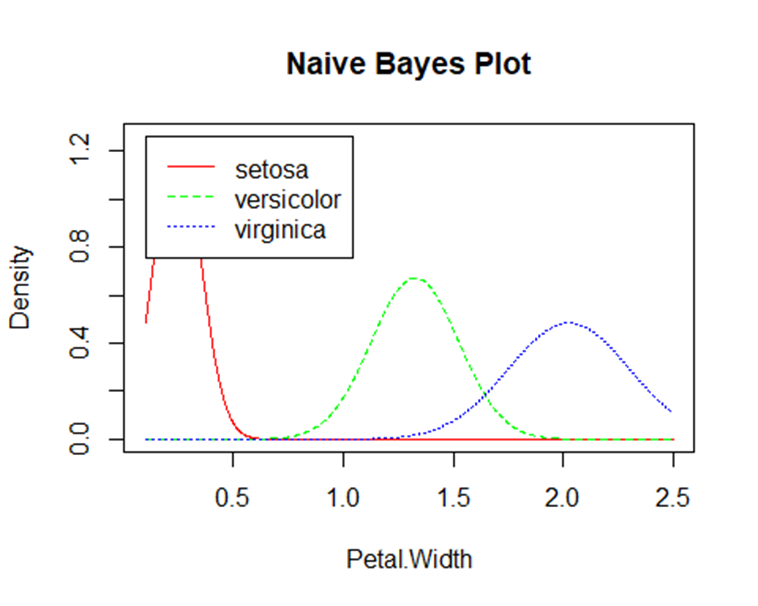
Kesimpulan
Bayesian dalam Machine Learning merupakan pendekatan yang memanfaatkan Teorema Bayes untuk memperbarui probabilitas suatu hipotesis berdasarkan data baru. Dengan menggabungkan prior (pengetahuan awal) dan likelihood (bukti dari data), diperoleh posterior yang lebih akurat dan mencerminkan ketidakpastian.
Metode ini fleksibel karena tidak hanya menghasilkan prediksi, tetapi juga memberikan ukuran probabilistik atas keyakinan terhadap prediksi tersebut. Naïve Bayes terbukti sederhana namun efektif, terutama dalam klasifikasi teks, deteksi spam, dan analisis sentimen.
Selain itu, Bayesian Linear Regression memungkinkan analisis parameter sebagai distribusi, sehingga prediksi lebih kaya dengan interval kepercayaan, sementara perbandingannya dengan Neural Networks menunjukkan bahwa Bayesian Regression lebih mudah diinterpretasikan, sedangkan Neural Networks unggul dalam pola non-linear.
Implementasi dalam R Studio menunjukkan bahwa algoritma Naïve Bayes mampu memberikan akurasi tinggi dalam klasifikasi data seperti iris dataset, sehingga menegaskan relevansinya dalam aplikasi dunia nyata.
Secara keseluruhan, Bayesian Machine Learning menjadi pendekatan penting untuk mengelola ketidakpastian, interpretasi probabilistik, dan efisiensi klasifikasi, yang menjadikannya landasan kuat dalam pengembangan model kecerdasan buatan modern.
Referensi:
https://rpubs.com/Henisulis/naivebayes
https://www.geeksforgeeks.org/machine-learning/naive-bayes-classifiers