

PENDAHULUAN
Pembangunan daerah pada dasarnya merupakan upaya untuk meningkatkan kesejahteraan masyarakat melalui pemanfaatan sumber daya secara adil, merata, dan berkelanjutan. Menurut Effendi (2002), pembangunan daerah tidak hanya berorientasi pada pertumbuhan ekonomi, tetapi juga pada peningkatan kualitas hidup masyarakat. Dalam konteks otonomi daerah, kemampuan suatu wilayah dalam membiayai pembangunan sangat ditentukan oleh Pendapatan Asli Daerah (PAD), khususnya realisasi pajak daerah yang menjadi salah satu komponen utama dalam sumber pembiayaan pembangunan.
Realisasi pajak daerah memiliki peran ganda, yaitu sebagai sumber penerimaan daerah sekaligus instrumen pengatur (regulatory function) yang memungkinkan pemerintah daerah mengoptimalkan pelayanan publik. Penelitian Taufik, Darmanto, dan Utami (2023) menunjukkan bahwa pajak daerah berpengaruh signifikan terhadap belanja modal pemerintah daerah. Hal ini membuktikan bahwa semakin tinggi realisasi pajak daerah, semakin besar pula kemampuan pemerintah daerah dalam melakukan investasi pembangunan, khususnya pada sektor infrastruktur dan pelayanan publik.
Di sisi lain, kesejahteraan masyarakat tidak dapat diukur hanya melalui aspek fiskal, tetapi juga melalui indikator pembangunan manusia. Badan Pusat Statistik (BPS) menggunakan Indeks Pembangunan Manusia (IPM) sebagai salah satu alat ukur kualitas hidup masyarakat, yang mencakup dimensi kesehatan, pendidikan, dan daya beli. Dengan demikian, realisasi pajak daerah yang optimal diharapkan dapat mendorong peningkatan IPM suatu wilayah, karena dana yang dihimpun melalui pajak dapat dialokasikan untuk layanan dasar, pengembangan pendidikan, serta peningkatan akses kesehatan.
Menurut Baskoro (2010), clustering merupakan salah satu metode dalam data mining yang bertujuan untuk mengelompokkan objek-objek ke dalam beberapa klaster. Klaster adalah sekumpulan objek data yang memiliki kemiripan tinggi satu sama lain dalam klaster yang sama, namun memiliki perbedaan (disimilar) dengan objek-objek data pada klaster lain. Dengan demikian, clustering dapat dipahami sebagai proses pengelompokan record, observasi, atau kasus ke dalam kelas-kelas berdasarkan tingkat kemiripannya. Algoritma clustering bekerja dengan membagi keseluruhan himpunan data menjadi subgrup yang relatif homogen, di mana kesamaan antar record dalam satu klaster dimaksimalkan, sementara kesamaan antar record di luar klaster diminimalkan.
Salah satu metode clustering yang banyak digunakan adalah Self Organizing Maps (SOM), yang diperkenalkan oleh Tuevo Kohonen pada tahun 1982. SOM merupakan jaringan saraf tiruan tanpa pengawasan (unsupervised neural network), sehingga disebut self organizing. Istilah maps digunakan karena metode ini bekerja dengan memetakan pembobotan input data ke dalam ruang representasi. Setiap node dalam jaringan SOM berusaha menyesuaikan diri dengan pola input yang diberikan. SOM juga dikenal dengan istilah Self Organizing Feature Maps karena metode ini menggunakan prinsip “feature” atau ciri khusus sebagai dasar pengelompokan, yang sekaligus membedakannya dari metode clustering lainnya.
METODE PENELITIAN
1. Jenis Penelitian
Jenis penelitian yang digunakan adalah penelitian kuantitatif dengan pendekatan deskriptif-eksploratif. Pendekatan deskriptif digunakan untuk memberikan gambaran umum kondisi setiap variabel di seluruh wilayah yang diteliti. Sementara itu, pendekatan eksploratif diterapkan untuk menemukan pola atau struktur tersembunyi dalam data melalui teknik pengelompokan (clustering) dengan metode Self Organizing Maps, dengan tujuan mengelompokkan wilayah berdasarkan kemiripan karakteristik sosial-ekonominya.
2. Jenis dan Sumber Data
Penelitian ini menggunakan data sekunder yang bersumber dari publikasi resmi Badan Pusat Statistika (BPS) Indonesia dan Direktorat Jenderal Perimbangan Keuangan, Kementerian Keungan (DJPK Kemenkeu) untuk periode tahun 2024. Penggunaan data dari BPS dan DJPK Kemenkeu dipilih karena merupakan sumber data resmi pemerintah yang kredibel, valid, dan diakui secara nasional, sehingga menjamin objektivitas dan keandalan data yang digunakan.
3. Definisi Operasional Variabel
1) Persentase Penduduk Miskin (PPM)
Menurut (Damayanti & Ratnasari, 2020), Persentase penduduk yang berada di bawah Garis Kemiskinan (GK). Seseorang dikategorikan miskin jika memiliki rata-rata pengeluaran per kapita per bulan di bawah Garis Kemiskinan. Variabel ini mengukur tingkat kemiskinan di suatu wilayah.
2) Tingkat Pengangguran Terbuka (TPT)
Menurut Annam dan Nasir (2023), Persentase jumlah pencari kerja yang tidak memiliki pekerjaan terhadap total angkatan kerja. Angkatan kerja mencakup penduduk usia kerja (15 tahun ke atas) yang sedang bekerja atau aktif mencari pekerjaan. Indikator ini mengukur ketersediaan lapangan kerja yang belum terserap oleh pasar tenaga kerja.
3) Indeks Gini (IG)
Indikator yang mengukur tingkat ketimpangan distribusi pengeluaran penduduk di suatu wilayah. Nilainya berkisar antara 0 (pemerataan sempurna) hingga 1 (ketimpangan sempurna). Semakin tinggi nilainya, semakin besar jurang ekonomi antara penduduk kaya dan miskin (Angkat & Saharuddin, 2023).
4) Angka Harapan Hidup (AHH)
Rata-rata perkiraan jumlah tahun yang akan dijalani oleh seorang bayi yang baru lahir, dengan asumsi pola mortalitas (tingkat kematian) pada saat kelahirannya berlaku sepanjang hidupnya. Variabel ini merupakan indikator penting untuk mengukur derajat kesehatan masyarakat (Arofah & Rohimah, 2019).
5) Rata-rata Lama Sekolah (RLS)
Jumlah tahun rata-rata yang telah dihabiskan oleh penduduk berusia 25 tahun ke atas untuk menempuh semua jenis pendidikan formal. Indikator ini mencerminkan tingkat pencapaian pendidikan dan kualitas sumber daya manusia di suatu daerah (Badan Pusat Statistik [BPS], 2018).
6) Pajak Daerah (PD)
Secara operasional diartikan sebagai total pendapatan yang diterima oleh pemerintah daerah dari semua jenis pajak daerah dalam satu tahun. Variabel ini digunakan sebagai proksi atau indikator untuk mengukur kapasitas fiskal dan tingkat aktivitas ekonomi suatu daerah (Febriani & Mildawati, 2021).
4. Teknik Analisis Data
1) Melakukan analisis statistika deskriptif terhadap variabel yang digunakan
Tahap awal adalah melakukan analisis deskriptif untuk memahami karakteristik dasar dari setiap variabel. Analisis ini mencakup perhitungan nilai rata-rata, standar deviasi, variansi, nilai minimum, dan maksimum untuk memberikan gambaran umum data sebelum dilakukan pengelompokan.
2) Melakukan standarisasi pada data
Sebelum proses clustering, dilakukan standardisasi data. Langkah ini krusial untuk menyamakan rentang nilai dan skala antar variabel. Dengan begitu, variabel dengan satuan dan rentang nilai yang besar tidak akan mendominasi proses perhitungan jarak dalam algoritma.
3) Melakukan pengelompokan dengan Self Organizing Maps pada perangkat lunak R
Proses inti adalah pengelompokan wilayah menggunakan algoritma Self Organizing Maps (SOM) yang diimplementasikan pada perangkat lunak R. SOM dipilih karena kemampuannya yang unggul dalam mereduksi dimensi, memvisualisasikan data multidimensi ke dalam peta dua dimensi, serta mengidentifikasi pola dan hubungan topologis antar data.
4) Menentukan cluster terbaik menggunakan indeks Dunn dan nilai Silhouette
Jumlah cluster terbaik tidak ditentukan secara subjektif, melainkan dievaluasi secara kuantitatif menggunakan Indeks Dunn dan nilai Silhouette. Jumlah cluster yang menghasilkan nilai Indeks Dunn tertinggi (menandakan cluster yang padat secara internal dan terpisah dengan baik secara eksternal) dan rata-rata nilai Silhouette tertinggi (menandakan keanggotaan objek dalam clusternya sudah tepat) akan dipilih sebagai solusi cluster akhir.
5) Melakukan interpretasi dari cluster yang terbentuk
Setelah jumlah cluster terbaik terbentuk, dilakukan tahap interpretasi untuk memberikan makna pada setiap cluster. Interpretasi ini didasarkan pada analisis nilai pusat (centroid) dari setiap variabel. Karakteristik dan profil unik dari masing-masing cluster akan diuraikan berdasarkan variabel-variabel mana yang memiliki nilai rata-rata dominan (jauh di atas atau di bawah rata-rata keseluruhan).
6) Penarikan kesimpulan
Tahap terakhir adalah penarikan kesimpulan berdasarkan hasil interpretasi profil cluster yang telah terbentuk. Kesimpulan akan merangkum temuan utama mengenai pengelompokan wilayah di Indonesia berdasarkan karakteristik sosial-ekonominya.
HASIL DAN PEMBAHASAN
1. Analisis Deskriptif
Sebagai analisis awal, disajikan statistika deskriptif untuk memberikan gambaran umum data. Langkah ini penting untuk memahami kecenderungan (tendensi sentral) dan sebaran (variasi) data pada setiap indikator antarprovinsi. Ringkasan statistik yang mencakup nilai minimum, maksimum, rata-rata, standar deviasi, dan variansi dari seluruh variabel dapat dilihat pada Tabel 1.
Tabel 1 Karakteristik Data
| Variabel | Min | Maks | Rataan | Std. Deviasi | Variansi |
| Persentase Penduduk Miskin | 3,80 | 29.66 | 10.67 | 6,37 | 40.54 |
| Tingkat Pengangguran Terbuka | 1,32 | 6,75 | 4,38 | 1,41 | 2,00 |
| Indeks Gini | 0,2350 | 0.4310 | 0,3406 | 0,0478 | 0,0023 |
| Angka Harapan Hidup | 64,75 | 75,53 | 70,58 | 2,66 | 7,10 |
| Rata-rata Lama Sekolah | 4,21 | 11,49 | 8,84 | 1,23 | 1,51 |
| Pajak Daerah | 211,2 | 44.448,1 | 7.178,1 | 11017.4 | 121.382.780,3 |
Berdasarkan data pada Tabel 1, terlihat adanya variasi yang signifikan pada berbagai indikator sosial-ekonomi antarprovinsi di Indonesia. Secara umum, kesenjangan paling tajam dan menjadi tantangan utama terjadi pada aspek kapasitas fiskal daerah dan tingkat kemiskinan. Indikator lainnya seperti pendidikan dan kesehatan, meskipun juga bervariasi, tidak menunjukkan disparitas seekstrem kedua indikator tersebut.
Kesenjangan paling nyata terdapat pada variabel Pajak Daerah, yang menunjukkan adanya jurang fiskal yang ekstrem. Rentang data yang sangat lebar antara nilai minimum (211,2) dan maksimum (44.448,1), serta didukung oleh standar deviasi yang luar biasa besar (11.017,4), mengonfirmasi adanya ketimpangan kapasitas ekonomi dan kemandirian fiskal antar daerah. Serupa dengan itu, Persentase Penduduk Miskin juga menunjukkan disparitas yang tinggi, dengan rentang antara 3,80% hingga 29,66% dan standar deviasi 6,37. Hal ini menegaskan bahwa meskipun rata-rata nasional berada di angka 10,67%, beberapa provinsi masih menghadapi tantangan kemiskinan yang sangat serius.
Jika dibandingkan, variasi pada Tingkat Pengangguran Terbuka jauh lebih rendah, seperti yang ditunjukkan oleh standar deviasi yang kecil (1,41). Ini mengindikasikan bahwa masalah pengangguran cenderung lebih merata persebarannya. Sementara itu, dari sisi ketimpangan pengeluaran, Indeks Gini dengan rata-rata 0,3406 mengklasifikasikan Indonesia pada tingkat ketimpangan sedang. Meskipun demikian, adanya nilai maksimum hingga 0,4310 menandakan bahwa beberapa provinsi masih mengalami distribusi pendapatan yang lebih timpang.
Pada sektor sosial, rata-rata Angka Harapan Hidup sudah relatif tinggi, yaitu 70,58 tahun. Namun, selisih lebih dari 10 tahun (satu dekade) antara provinsi dengan angka terendah dan tertinggi menunjukkan masih adanya ketidakmerataan akses dan kualitas layanan kesehatan. Dari sisi pendidikan, Rata-rata Lama Sekolah yang hanya mencapai 8,84 tahun menjadi catatan penting, karena ini berarti mayoritas penduduk secara rata-rata belum menamatkan pendidikan menengah atas atau wajib belajar 12 tahun.
Secara keseluruhan, analisis deskriptif ini menegaskan bahwa tantangan pembangunan di Indonesia sangat diwarnai oleh kesenjangan ekonomi yang tajam, terutama dalam hal kemiskinan dan kapasitas fiskal. Kesenjangan ini jauh lebih menonjol dibandingkan dengan variasi pada indikator sosial seperti pendidikan dan kesehatan, yang meskipun masih ada, cenderung lebih seragam.
1) Persentase Penduduk Miskin (PPM)

Gambar 1 Persentase Penduduk Miskin
Berdasarkan Gambar 1, terlihat jelas adanya disparitas yang sangat tajam mengenai persentase penduduk miskin antarprovinsi di Indonesia. Pola yang paling menonjol dari data ini adalah adanya konsentrasi geografis yang kuat, di mana persentase penduduk miskin yang tinggi secara signifikan terpusat di wilayah timur Indonesia.
Di satu sisi, persentase penduduk miskin yang sangat tinggi terkonsentrasi di Kawasan Timur Indonesia. Provinsi-provinsi seperti Papua Pegunungan, Papua, dan Nusa Tenggara Timur mencatat persentase penduduk miskin yang jauh di atas rata-rata nasional, bahkan mendekati 30% pada kasus tertinggi. Kondisi ini berbanding terbalik dengan provinsi-provinsi di Kawasan Barat Indonesia yang menjadi pusat perekonomian. Wilayah seperti DKI Jakarta, Bali, dan Kepulauan Riau secara konsisten memiliki persentase penduduk miskin terendah, yaitu di bawah 5%.
2) Tingkat Pengangguran Terbuka (TPT)
Gambar 2 menunjukkan variasi tingkat pengangguran terbuka antarprovinsi di Indonesia. Provinsi dengan urbanisasi tinggi seperti DKI Jakarta, Jawa Barat, dan Kepulauan Riau tampak memiliki pengangguran lebih tinggi dibanding rata-rata nasional, yakni bisa mencapai lebih dari 6%. Sebaliknya, provinsi di kawasan timur dan sebagian Sumatera memiliki tingkat pengagguran lebih rendah, bahkan ada yang mendekati 1%.

Gambar 2 Tingkat Pengangguran Terbuka
Pola ini menegaskan bahwa pengangguran cenderung menjadi masalah di daerah perkotaan dan pusat ekonomi, sementara wilayah dengan aktivitas ekonomi berbasis sektor primer relatif lebih kecil penganggurannya.
3) Indeks Gini (IG)

Gambar 3 Indeks Gini
Gambar 3 menunjukkan tingkat ketimpangan pendapatan yang bervariasi di seluruh provinsi Indonesia, yang diukur menggunakan Indeks Gini. Terlihat bahwa sebagian besar provinsi memiliki nilai Indeks Gini yang terkonsentrasi di rentang 0,300 hingga 0,400. Meskipun bervariasi, nilai di banyak provinsi cenderung mengelompok dalam rentang tersebut. Perbedaan yang signifikan justru terlihat pada nilai-nilai ekstremnya. Provinsi yang merupakan pusat ekonomi dan urbanisasi seperti DI Yogyakarta, DKI Jakarta, Jawa Barat, dan Gorontalo mencatat nilai Indeks Gini tertinggi, yaitu di atas 0,400. Sebaliknya, nilai terendah tercatat di Provinsi Kepulauan Bangka Belitung, dengan angka sekitar 0,235.
Pola ini menyoroti sebuah temuan penting bahwa provinsi dengan tingkat perekonomian yang lebih maju tidak serta-merta memiliki distribusi pendapatan yang merata. Justru, data ini menunjukkan bahwa pusat-pusat pertumbuhan ekonomi tersebut cenderung menghadapi tantangan ketimpangan pendapatan yang lebih besar dibandingkan dengan beberapa daerah lainnya.
4) Angka Harapan Hidup (AHH)
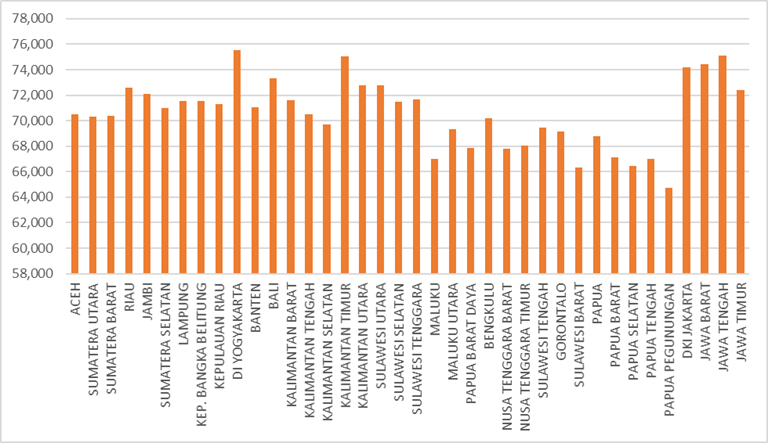
Gambar 4 Angka Harapan Hidup
Gambar 4 menunjukkan adanya perbedaan Angka Harapan Hidup (AHH) antarprovinsi di Indonesia, yang merefleksikan variasi dalam kualitas kesehatan dan kesejahteraan. Sebagian besar provinsi menunjukkan pencapaian yang relatif baik, dengan AHH yang terkonsentrasi pada kisaran 70 hingga 74 tahun, menandakan standar kesehatan yang cukup merata di banyak wilayah. Meskipun demikian, terdapat kesenjangan yang signifikan pada nilai-nilai ekstrem. Provinsi DI Yogyakarta menonjol sebagai wilayah dengan AHH tertinggi, yang mencapai lebih dari 75 tahun. Di sisi lain, beberapa provinsi di kawasan timur Indonesia, khususnya Papua Pegunungan dan Papua, mencatat AHH terendah, yaitu sekitar 65 tahun. Perbedaan ini menciptakan rentang kesenjangan kualitas hidup hingga 10 tahun antara wilayah dengan performa terbaik dan terendah.
Pola ini secara jelas mencerminkan adanya disparitas dalam kualitas dan aksesibilitas layanan kesehatan, serta tingkat kesejahteraan secara umum. Provinsi-provinsi yang lebih maju, terutama di Pulau Jawa, cenderung memiliki AHH yang lebih tinggi. Sebaliknya, wilayah yang masih menghadapi tantangan dalam penyediaan fasilitas kesehatan dan pembangunan manusia menunjukkan AHH yang lebih rendah.
5) Rata-rata Lama Sekolah (RLS)
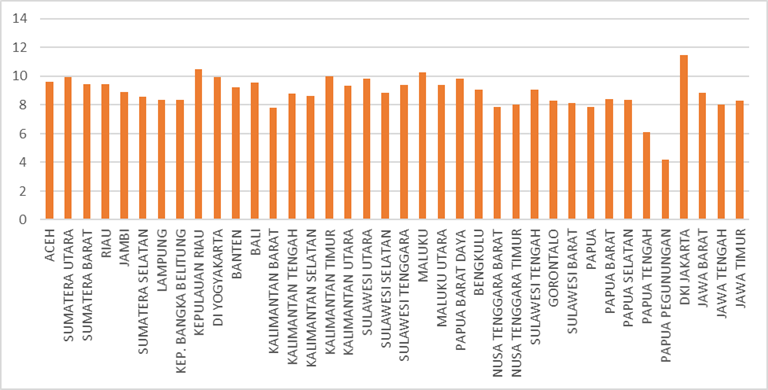
Gambar 5 Rata-rata Lama Sekolah
Gambar 5 menunjukkan adanya kesenjangan capaian pendidikan antarprovinsi di Indonesia, yang diukur melalui Rata-rata Lama Sekolah (RLS). Secara umum, sebagian besar provinsi berada pada level pencapaian yang serupa, dengan RLS berkisar antara 8 hingga 10 tahun. Angka ini mengindikasikan bahwa rata-rata penduduk di banyak wilayah telah menyelesaikan pendidikan setingkat SMP, namun belum menamatkan SMA. Perbedaan yang tajam terlihat pada nilai-nilai ekstrem. Provinsi seperti DKI Jakarta, dengan RLS di atas 11 tahun, menunjukkan capaian tertinggi, mendekati target wajib belajar 12 tahun atau setara lulus SMA. Hal ini sangat kontras dengan kondisi di Papua Pegunungan dan Papua, di mana RLS-nya hanya berkisar 4 hingga 6 tahun. Angka yang rendah ini menandakan bahwa rata-rata penduduk di sana bahkan belum menyelesaikan pendidikan dasar (SD).
Kondisi ini menegaskan adanya jurang pendidikan yang sangat dalam di Indonesia. Data tersebut mencerminkan tantangan besar dalam pemerataan akses dan kualitas pendidikan, khususnya antara wilayah perkotaan yang maju seperti di Jawa dengan beberapa provinsi di kawasan timur yang pembangunannya masih perlu dikejar.
6) Pajak Daerah (PD)

Gambar 6 Pajak Daerah
Gambar 6 menggambarkan adanya jurang fiskal yang sangat dalam antarprovinsi di Indonesia. Terdapat ketimpangan ekstrem di mana ada empat provinsi yaitu DKI Jakarta, Jawa Barat,Jawa Timur dan Jawa tengah berada pada level yang jauh melampaui provinsi lainnya. Keempat provinsi tersebut sangat kontras dengan sebagian besar provinsi lain di Indonesia. Mayoritas provinsi hanya mampu menghimpun pendapatan pajak yang nilainya sangat kecil jika dibandingkan. Beberapa provinsi, terutama di kawasan timur, bahkan mencatatkan penerimaan yang sangat minimal jika dibandingkan dengan empat raksasa ekonomi di Jawa.
Kesenjangan yang mencolok ini secara langsung mencerminkan konsentrasi aktivitas ekonomi seperti industri, perdagangan, dan jasa yang sangat terpusat di Pulau Jawa. Kapasitas fiskal yang sangat besar ini memberikan provinsi-provinsi tersebut kemampuan belanja yang jauh lebih tinggi untuk membiayai pembangunan dan layanan publik. Sebaliknya, daerah lain dengan basis ekonomi terbatas memiliki ruang fiskal yang jauh lebih sempit, yang menjadi salah satu akar dari isu ketimpangan pembangunan antarwilayah di Indonesia.
2. Standarisasi Data
Standarisasi data adalah proses transformasi nilai-nilai dari berbagai variabel ke dalam satu skala yang seragam. Dalam metode Self-Organizing Maps (SOM), langkah ini sangat penting karena dua alasan utama: pertama, untuk menghilangkan bias yang dapat timbul akibat perbedaan rentang nilai antarvariabel (misalnya, membandingkan Pajak Daerah dalam miliaran dengan Rata-rata Lama Sekolah dalam satuan tahun). Kedua, standarisasi membantu mempercepat proses konvergensi algoritma, sehingga model dapat belajar dengan lebih efisien.
Salah satu metode yang umum digunakan adalah standardisasi Z-score, yang dihitung menggunakan formula:

Di mana:
-
 adalah nilai setelah standarisasi
adalah nilai setelah standarisasi  adalah nilai data asli
adalah nilai data asli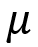 adalah nilai rata-rata (mean) dari seluruh data pada variabel tersebut
adalah nilai rata-rata (mean) dari seluruh data pada variabel tersebut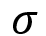 adalah standar deviasi dari variabel tersebut
adalah standar deviasi dari variabel tersebut
Hasil dari standarisasi ini mudah diinterpretasikan, nilai positif menunjukkan bahwa data asli berada di atas nilai rata-ratanya, sedangkan nilai negatif berarti data tersebut berada di bawah rata-rata. Semakin besar nilai absolutnya (semakin jauh dari nol), semakin signifikan pula simpangan data tersebut dari rata-ratanya. Hasil standarisasi data yang digunakan dalam penelitian ini disajikan pada Tabel 2.
Tabel 2 Hasil Standarisasi Data
| PROVINSI | PPM | TPT | GR | AHH | RLS | PD |
| Aceh | 0,310246 | 0,968916 | -0,97638 | -0,03433 | 0,650494 | -0,424138 |
| Sumatera Utara | -0,54576 | 0,862851 | -0,72512 | -0,09252 | 0,886687 | 0,3833651 |
| Sumatera Barat | -0,82377 | 0,968916 | -1,12294 | -0,07375 | 0,487603 | -0,353869 |
| Riau | -0,67613 | -0,48064 | -0,72512 | 0,748389 | 0,479458 | -0,07948 |
| Jambi | -0,53477 | 0,070896 | -0,53668 | 0,568195 | 0,047796 | -0,42565 |
| Sumatera Selatan | -0,0243 | -0,36751 | -0,20167 | 0,149619 | -0,22098 | -0,013086 |
| Bengkulu | 0,291399 | -0,89783 | 0,04959 | -0,14883 | 0,16182 | -0,546756 |
| Lampung | -0,00703 | -0,13416 | -0,82981 | 0,365476 | -0,39201 | -0,23195 |
| Kep. Bangka Belitung | -0,87717 | 0,176962 | -2,21173 | 0,359845 | -0,41645 | -0,53722 |
| Kepulauan Riau | -0,92429 | 1,421462 | 0,342724 | 0,265994 | 1,350928 | -0,294589 |
| Dki Jakarta | -1,02481 | 1,294184 | 1,892145 | 1,352791 | 2,157241 | 3,3828317 |
| Jawa Barat | -0,56304 | 1,676019 | 1,829331 | 1,439134 | 0,023362 | 3,1965271 |
| Jawa Tengah | -0,17038 | 0,283027 | 0,489291 | 1,698163 | -0,66893 | 1,3842786 |
| Di Yogyakarta | -0,04158 | -0,63621 | 1,829331 | 1,859587 | 0,878543 | -0,283189 |
| Jawa Timur | -0,17352 | -0,13416 | 0,677734 | 0,682693 | -0,45717 | 2,3013628 |
| Banten | -0,77979 | 1,626522 | 0,3846 | 0,183405 | 0,316567 | 0,9767191 |
| Bali | -1,07822 | -1,83121 | 0,154281 | 1,037451 | 0,569049 | 0,721438 |
| Nusa Tenggara Barat | 0,195588 | -1,16653 | 0,489291 | -1,0498 | -0,7911 | -0,370592 |
| Nusa Tenggara Timur | 1,312327 | -0,96147 | -0,51574 | -0,95407 | -0,66893 | -0,477796 |
| Kalimantan Barat | -0,6934 | 0,339595 | -0,55762 | 0,384247 | -0,8644 | -0,301484 |
| Kalimantan Tengah | -0,8489 | -0,26144 | -0,767 | -0,03808 | -0,02551 | -0,379645 |
| Kalimantan Selatan | -1,04366 | -0,12709 | -0,89263 | -0,3309 | -0,18025 | -0,150665 |
| Kalimantan Timur | -0,80963 | 0,537584 | -0,64137 | 1,68127 | 0,959988 | 0,3261818 |
| Kalimantan Utara | -0,83005 | -0,33922 | -1,70921 | 0,825347 | 0,414302 | -0,560622 |
| Sulawesi Utara | -0,62272 | 1,039627 | 0,133343 | 0,814085 | 0,813386 | -0,470655 |
| Sulawesi Tengah | 0,058941 | -1,01804 | -0,66231 | -0,41724 | 0,16182 | -0,373497 |
| Sulawesi Selatan | -0,45466 | -0,13416 | 0,405538 | 0,339198 | 0,015217 | 0,0474605 |
| Sulawesi Tenggara | -0,00546 | -0,91198 | 0,510229 | 0,403017 | 0,471314 | -0,486179 |
| Gorontalo | 0,503438 | -0,88369 | 1,515259 | -0,53925 | -0,44902 | -0,593941 |
| Sulawesi Barat | 0,007109 | -1,20189 | -0,22261 | -1,59789 | -0,56305 | -0,602254 |
| Maluku | 0,803433 | 1,223473 | -1,03919 | -1,34074 | 1,155458 | -0,580707 |
| Maluku Utara | -0,72796 | -0,2473 | -0,9345 | -0,47168 | 0,430591 | -0,531419 |
| Papua | 1,166256 | 1,485101 | 1,347754 | -0,67627 | -0,79924 | -0,602338 |
| Papua Barat | 1,637453 | -0,17659 | 0,928991 | -1,30507 | -0,36758 | -0,60887 |
| Papua Barat Daya | 0,987201 | 1,485101 | 0,133343 | -1,02352 | 0,797097 | -0,619747 |
| Papua Selatan | 1,364159 | -0,23316 | 1,745578 | -1,5397 | -0,37572 | -0,627759 |
| Papua Tengah | 2,659952 | -1,15239 | 0,300848 | -1,33886 | -2,2164 | -0,559716 |
| Papua Pegunungan | 2,983508 | -2,16355 | 0,112405 | -2,1854 | -3,77201 | -0,632351 |
3. Pengelompokan dengan Self Organizing Maps (SOM)
Langkah pertama yang dilakukan sebelum pengelompokan dengan SOM ialah Trining Progress. Proses pelatihan (training) pada metode SOM bertujuan untuk mengorganisasi neuron-neuron di dalam peta (map) agar dapat merepresentasikan struktur data asli. Grafik Training Progress Gambar 7 memvisualisasikan proses ini dengan menunjukkan bagaimana rata-rata jarak dari setiap data ke neuron terdekatnya (mean distance to closest unit) menurun seiring dengan berjalannya iterasi. Penurunan nilai ini menandakan bahwa bobot neuron pada peta secara bertahap telah berhasil menyesuaikan diri dengan pola pada data.

Gambar 7 Training Progress
Pada Gambar 7, terlihat bahwa di awal proses pelatihan, rata-rata jarak masih tinggi (di atas 0,10), yang menunjukkan peta belum terorganisasi dengan baik. Seiring bertambahnya jumlah iterasi, terjadi tren penurunan yang jelas dan signifikan. Proses konvergensi menjadi sangat nyata setelah iterasi ke-1500, di mana rata-rata jarak turun drastis dan kemudian stabil pada level yang sangat rendah (sekitar 0,04). Kondisi yang stabil pada akhir proses pelatihan (menuju iterasi ke-2000) ini mengindikasikan bahwa model SOM telah konvergen. Artinya, proses pelatihan telah berhasil dan peta yang terbentuk sudah konsisten dan dapat diandalkan untuk tahap pengelompokan data selanjutnya.
1) Hasil Pengelompokan untuk 2 Cluster
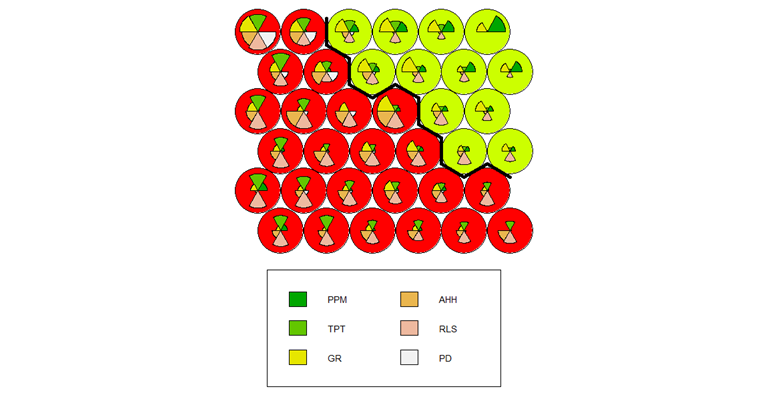
Gambar 8 Diagram Fan untuk Pembentukan 2 Cluster
Gambar 8 menampilkan visualisasi SOM Codes Plot, yang berfungsi untuk memetakan hasil pengelompokan dari setiap neuron. Setiap heksagon pada peta mewakili satu neuron, dan diagram pai (pie chart) di dalamnya menggambarkan vektor bobot (weight vector) dari neuron tersebut. Ukuran dari setiap irisan pai menunjukkan besarnya nilai rata-rata dari masing-masing variabel (sesuai legenda) yang terasosiasi dengan neuron tersebut.
Berdasarkan pewarnaan pada peta, neuron-neuron tersebut telah dikelompokkan menjadi dua cluster yang ditandai dengan warna merah dan kuning. Adanya batas yang jelas di antara kedua kelompok warna secara visual menunjukkan bahwa terdapat perbedaan karakteristik yang tegas antara kedua cluster tersebut. Hasil pengelompokan provinsi dapat dilihat pada Tabel 3.
Tabel 3 Hasil Pengelompokan 2 Cluster
| Cluster | Jumlah Anggota | Anggota |
| 1 (Merah) | 27 | Aceh, Sumatera Utara, Sumatera Barat, Riau, Jambi, Sumatera Selatan, Lampung, Kep. Bangka Belitung, Kepulauan Riau, Dki Jakarta, Jawa Barat, Jawa Tengah, Di Yogyakarta, Jawa Timur, Banten, Bali, Kalimantan Barat, Kalimantan Tengah, Kalimantan Selatan, Kalimantan Timur, Kalimantan Utara, Sulawesi Utara, Sulawesi Selatan, Sulawesi Tenggara, Maluku, Maluku Utara, Papua Barat Daya. |
| 2 (Kuning) | 11 | Bengkulu, Nusa Tenggara Barat, Nusa Tenggara Timur, Sulawesi Tengah, Gorontalo, Sulawesi Barat, Papua, Papua Barat, Papua Selatan, Papua Tengah, Papua Pegunungan. |
Tabel 3 menyajikan hasil akhir pengelompokan yang membagi 38 provinsi di Indonesia menjadi dua cluster yang berbeda. Cluster 1 merupakan kelompok mayoritas yang beranggotakan 27 provinsi. Secara geografis, cluster ini didominasi oleh provinsi-provinsi yang berada di Pulau Jawa, Sumatera, dan Kalimantan. Sementara itu, Cluster 2 adalah kelompok yang lebih kecil dengan 11 provinsi anggota. Mayoritas anggota cluster ini berasal dari Kawasan Timur Indonesia, khususnya provinsi-provinsi di Kepulauan Nusa Tenggara dan Papua, serta beberapa dari Sulawesi.
2) Hasil Pengelompokan untuk 3 Cluster

Gambar 9 Diagram Fan untuk Pembentukan 3 Cluster
Gambar 9 menampilkan visualisasi SOM Codes Plot untuk hasil pengelompokan 3 cluster. Seperti pada visualisasi sebelumnya, setiap heksagon pada peta mewakili satu neuron, dan diagram pai (pie chart) di dalamnya menggambarkan vektor bobot (weight vector) dari neuron tersebut. Ukuran dari setiap irisan pai menunjukkan besarnya nilai rata-rata dari masing-masing variabel (sesuai legenda) yang menjadi ciri khas neuron tersebut.
Berdasarkan pewarnaan pada peta, neuron-neuron tersebut telah dikelompokkan menjadi tiga cluster utama yang ditandai dengan warna merah, kuning, dan hijau. Terlihat bahwa setiap cluster membentuk wilayah yang jelas dan terpisah di dalam peta, yang menunjukkan adanya perbedaan karakteristik yang tegas di antara ketiga kelompok tersebut. Anggota dari masing-masing cluster dijelaskan pada Tabel 4.
Tabel 4 Hasil Pengelompokan 3 Cluster
| Cluster | Jumlah Anggota | Anggota |
| 1 (Merah) | 23 | Aceh, Sumatera Utara, Sumatera Barat, Riau, Jambi, Sumatera Selatan, Lampung, Kep. Bangka Belitung, Kepulauan Riau, Di Yogyakarta, Banten, Bali, Kalimantan Barat, Kalimantan Tengah, Kalimantan Selatan, Kalimantan Timur, Kalimantan Utara, Sulawesi Utara, Sulawesi Selatan, Sulawesi Tenggara, Maluku, Maluku Utara, Papua Barat Daya. |
| 2 (Kuning) | 11 | Bengkulu, Nusa Tenggara Barat, Nusa Tenggara Timur, Sulawesi Tengah, Gorontalo, Sulawesi Barat, Papua, Papua Barat, Papua Selatan, Papua Tengah, Papua Pegunungan. |
| 3 (Hijau) | 4 | Dki Jakarta, Jawa Barat, Jawa Tengah, Jawa Timur. |
Tabel 4 menyajikan hasil pengelompokan yang membagi 38 provinsi di Indonesia menjadi tiga cluster yang berbeda. Kelompok pertama, yaitu Cluster 1, merupakan kelompok terbesar dengan 23 provinsi anggota. Anggota cluster ini sebagian besar berlokasi di Pulau Sumatera, Kalimantan, dan sebagian Sulawesi. Kelompok kedua, Cluster 2, terdiri dari 11 provinsi yang mayoritas berasal dari Kawasan Timur Indonesia, khususnya provinsi-provinsi di Kepulauan Nusa Tenggara dan Papua, serta beberapa dari Sulawesi. Kelompok terakhir, Cluster 3, adalah yang terkecil dengan 4 provinsi anggota. Seluruh anggota cluster ini berlokasi di Pulau Jawa, yaitu DKI Jakarta, Jawa Barat, Jawa Tengah, dan Jawa Timur. Analisis lebih lanjut mengenai karakteristik yang membedakan ketiga cluster ini akan dibahas pada bagian berikutnya.
3) Hasil Pengelompokan untuk 4 Cluster
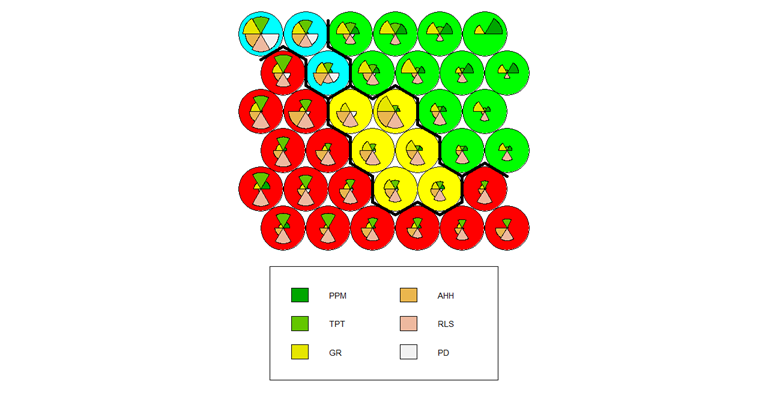
Gambar 10 Diagram Fan untuk Pembentukan 4 Cluster
Gambar 10 menampilkan visualisasi SOM Codes Plot untuk hasil pengelompokan 4 cluster. Sebagaimana sebelumnya, setiap heksagon pada peta mewakili satu neuron, dan diagram pai di dalamnya menggambarkan vektor bobot (weight vector) dari neuron tersebut. Ukuran dari setiap irisan pai menunjukkan besarnya nilai rata-rata dari masing-masing variabel (sesuai legenda) yang menjadi ciri khas neuron tersebut.
Berdasarkan pewarnaan pada peta, neuron-neuron tersebut telah dikelompokkan menjadi empat cluster utama yang ditandai dengan warna merah, kuning, hijau, dan biru muda. Terlihat bahwa setiap cluster membentuk wilayah yang jelas dan terpisah di dalam peta, yang menunjukkan adanya perbedaan karakteristik yang tegas di antara keempat kelompok tersebut. Anggota dari masing-masing cluster dijelaskan pada Tabel 5.
Tabel 5 Hasil Pengelompokan 4 Cluster
| Cluster | Jumlah Anggota | Anggota |
| 1 (Merah) | 18 | Aceh, Sumatera Utara, Sumatera Barat, Riau, Jambi, Lampung, Kep. Bangka Belitung, Kepulauan Riau, Banten, Kalimantan Barat, Kalimantan Tengah, Kalimantan Selatan, Kalimantan Timur, Kalimantan Utara, Sulawesi Utara, Maluku, Maluku Utara, Papua Barat Daya. |
| 2 (Kuning) | 5 | Sumatera Selatan, Di Yogyakarta, Bali, Sulawesi Selatan, Sulawesi Tenggara, |
| 3 (Hijau) | 11 | Bengkulu, Nusa Tenggara Barat, Nusa Tenggara Timur, Sulawesi Tengah, Gorontalo, Sulawesi Barat, Papua, Papua Barat, Papua Selatan, Papua Tengah, Papua Pegunungan. |
| 4 (Biru Muda) | 4 | Dki Jakarta, Jawa Barat, Jawa Tengah, Jawa Timur. |
Tabel 5 menyajikan hasil pengelompokan yang membagi 38 provinsi di Indonesia menjadi empat cluster yang berbeda. Kelompok pertama, Cluster 1 (Merah), merupakan yang terbesar dengan 18 provinsi anggota, yaitu Aceh, Sumatera Utara, Sumatera Barat, Riau, Jambi, Lampung, Kep. Bangka Belitung, Kepulauan Riau, Banten, Kalimantan Barat, Kalimantan Tengah, Kalimantan Selatan, Kalimantan Timur, Kalimantan Utara, Sulawesi Utara, Maluku, Maluku Utara, dan Papua Barat Daya. Kelompok berikutnya, Cluster 3 (Hijau), beranggotakan 11 provinsi: Bengkulu, Nusa Tenggara Barat, Nusa Tenggara Timur, Sulawesi Tengah, Gorontalo, Sulawesi Barat, Papua, Papua Barat, Papua Selatan, Papua Tengah, dan Papua Pegunungan.
Dua cluster lainnya memiliki anggota yang lebih sedikit. Cluster 2 (Kuning) terdiri dari 5 provinsi, yaitu Sumatera Selatan, DI Yogyakarta, Bali, Sulawesi Selatan, dan Sulawesi Tenggara. Sementara itu, Cluster 4 (Biru) adalah kelompok terkecil dengan 4 provinsi, yaitu DKI Jakarta, Jawa Barat, Jawa Tengah, dan Jawa Timur.
4) Hasil Pengelompokan untuk 5 Cluster
Gambar 11 menampilkan visualisasi SOM Codes Plot untuk hasil pengelompokan 5 cluster. Seperti pada visualisasi sebelumnya, setiap heksagon pada peta mewakili satu neuron, dan diagram pai di dalamnya menggambarkan vektor bobot (weight vector) dari neuron tersebut. Ukuran dari setiap irisan pai menunjukkan besarnya nilai rata-rata dari masing-masing variabel (sesuai legenda) yang menjadi ciri khas neuron tersebut.

Gambar 11 Diagram Fan untuk Pembentukan 5 Cluster
Berdasarkan pewarnaan pada peta, neuron-neuron tersebut telah dikelompokkan menjadi lima cluster utama yang ditandai dengan warna merah, kuning, hijau, biru muda, dan biru tua. Terlihat bahwa setiap cluster membentuk wilayah yang jelas dan terpisah di dalam peta, yang menunjukkan adanya perbedaan karakteristik yang tegas di antara kelima kelompok tersebut. Anggota dari masing-masing cluster dijelaskan pada Tabel 6.
Tabel 6 Hasil Pengelompokan 5 Cluster
| Cluster | Jumlah Anggota | Anggota |
| 1 (Merah) | 18 | Aceh, Sumatera Utara, Sumatera Barat, Riau, Jambi, Lampung, Kep. Bangka Belitung, Kepulauan Riau, Banten, Kalimantan Barat, Kalimantan Tengah, Kalimantan Selatan, Kalimantan Timur, Kalimantan Utara, Sulawesi Utara, Maluku, Maluku Utara, Papua Barat Daya. |
| 2 (Kuning) | 5 | Sumatera Selatan, Di Yogyakarta, Bali, Sulawesi Selatan, Sulawesi Tenggara, |
| 3 (Hijau) | 9 | Bengkulu, Nusa Tenggara Barat, Nusa Tenggara Timur, Sulawesi Tengah, Gorontalo, Sulawesi Barat, Papua, Papua Barat, Papua Selatan. |
| 4 (Biru Muda) | 4 | Dki Jakarta, Jawa Barat, Jawa Tengah, Jawa Timur. |
| 5 (Biru Tua) | 2 | Papua Tengah, Papua Pegunungan. |
Tabel 6 menyajikan hasil pengelompokan yang membagi 38 provinsi di Indonesia menjadi lima cluster yang berbeda. Kelompok pertama, Cluster 1 (Merah), merupakan yang terbesar dengan 18 provinsi anggota, yaitu: Aceh, Sumatera Utara, Sumatera Barat, Riau, Jambi, Lampung, Kep. Bangka Belitung, Kepulauan Riau, Banten, Kalimantan Barat, Kalimantan Tengah, Kalimantan Selatan, Kalimantan Timur, Kalimantan Utara, Sulawesi Utara, Maluku, Maluku Utara, dan Papua Barat Daya. Kelompok berikutnya, Cluster 3 (Hijau), beranggotakan 9 provinsi, yaitu: Bengkulu, Nusa Tenggara Barat, Nusa Tenggara Timur, Sulawesi Tengah, Gorontalo, Sulawesi Barat, Papua, Papua Barat, dan Papua Selatan.
Tiga cluster lainnya memiliki anggota yang lebih sedikit. Cluster 2 (Kuning) terdiri dari 5 provinsi: Sumatera Selatan, DI Yogyakarta, Bali, Sulawesi Selatan, dan Sulawesi Tenggara. Selanjutnya, Cluster 4 (Biru Muda) beranggotakan 4 provinsi: DKI Jakarta, Jawa Barat, Jawa Tengah, dan Jawa Timur. Terakhir, Cluster 5 (Biru Tua) adalah kelompok terkecil dengan 2 provinsi: Papua Tengah dan Papua Pegunungan.
5) Hasil Pengelompokan untuk 6 Cluster

Gambar 12 Diagram Fan untuk Pembentukan 6 Cluster
Gambar 12 menampilkan visualisasi SOM Codes Plot untuk hasil pengelompokan 6 cluster. Sebagaimana sebelumnya, setiap heksagon pada peta mewakili satu neuron, dan diagram pai di dalamnya menggambarkan vektor bobot (weight vector) dari neuron tersebut. Ukuran dari setiap irisan pai menunjukkan besarnya nilai rata-rata dari masing-masing variabel (sesuai legenda) yang menjadi ciri khas neuron tersebut.
Berdasarkan pewarnaan pada peta, neuron-neuron tersebut telah dikelompokkan menjadi enam cluster utama yang ditandai dengan warna merah, kuning, hijau, biru muda, biru tua, dan Ungu. Terlihat bahwa setiap cluster membentuk wilayah yang jelas dan terpisah di dalam peta, yang menunjukkan adanya perbedaan karakteristik yang tegas di antara keenam kelompok tersebut. Anggota dari masing-masing cluster akan dijelaskan pada Tabel 7.
Tabel 7 Hasil Pengelompokan 6 Cluster
| Cluster | Jumlah Anggota | Anggota |
| 1 (Merah) | 16 | Bengkulu, Nusa Tenggara Barat, Nusa Tenggara Timur, Sulawesi Tengah, Sulawesi Barat. |
| 2 (Kuning) | 2 | Maluku, Papua Barat Daya. |
| 3 (Hijau) | 5 | Sumatera Selatan, Di Yogyakarta, Bali, Sulawesi Selatan, Sulawesi Tenggara, |
| 4 (Biru Muda) | 9 | Bengkulu, Nusa Tenggara Barat, Nusa Tenggara Timur, Sulawesi Tengah, Gorontalo, Sulawesi Barat, Papua, Papua Barat, Papua Selatan. |
| 5 (Biru Tua) | 4 | Dki Jakarta, Jawa Barat, Jawa Tengah, Jawa Timur. |
| 6 (Ungu) | 2 | Papua Tengah, Papua Pegunungan. |
Tabel 7 menyajikan hasil pengelompokan yang membagi 38 provinsi di Indonesia menjadi enam cluster yang berbeda. Berdasarkan tabel tersebut, Cluster 1 (Merah) tercatat memiliki 16 anggota. Cluster 2 (Kuning) beranggotakan 2 provinsi, yaitu Maluku dan Papua Barat Daya. Selanjutnya, Cluster 3 (Hijau) terdiri dari 5 provinsi: Sumatera Selatan, DI Yogyakarta, Bali, Sulawesi Selatan, dan Sulawesi Tenggara. Cluster 4 (Biru Muda) tercatat memiliki 9 anggota. Cluster 5 (Biru Tua) beranggotakan 4 provinsi, yaitu DKI Jakarta, Jawa Barat, Jawa Tengah, dan Jawa Timur. Terakhir, Cluster 6 (Ungu) adalah kelompok terkecil dengan 2 provinsi: Papua Tengah dan Papua Pegunungan.
4. Validasi Cluster Optimum
Untuk menentukan jumlah cluster yang paling optimal dan valid secara statistik, dilakukan uji validasi menggunakan Indeks Dunn dan Silhouette Score. Indeks Dunn mengevaluasi kualitas pengelompokan dengan mengukur rasio antara jarak minimum antar-cluster dengan jarak maksimum di dalam cluster. Sementara itu, Silhouette Score mengukur seberapa baik setiap objek ditempatkan dalam cluster-nya. Untuk kedua metrik ini, nilai yang lebih tinggi menunjukkan struktur pengelompokan yang lebih baik, yaitu cluster yang padat (kompak) dan terpisah dengan jelas satu sama lain.
Tabel 8 Hasil Uji Validasi Cluster
| Jumlah Cluster | Dunn | Silhouette |
| 2 | 0,2220 | 0,3158 |
| 3 | 0,2631 | 0,3207 |
| 4 | 0,2388 | 0,2607 |
| 5 | 0,1551 | 0,1667 |
| 6 | 0,2069 | 0,2372 |
Hasil uji validasi yang disajikan pada Tabel 8 menunjukkan bahwa solusi dengan 3 cluster secara konsisten mencapai nilai tertinggi untuk kedua metrik, dengan Indeks Dunn sebesar 0,2631 dan Silhouette Score sebesar 0,3207. Nilai ini secara kuantitatif lebih unggul dibandingkan dengan solusi 2, 4, 5, ataupun 6 cluster.
Berdasarkan bukti validasi ini, maka pengelompokan dengan 3 cluster dipilih sebagai model yang paling optimal dan valid. Struktur ini dianggap paling tepat untuk menggambarkan dan mengelompokkan pola kondisi sosial-ekonomi antarprovinsi di Indonesia karena memiliki tingkat kepadatan internal dan keterpisahan eksternal yang terbaik.
5. Pemetaan Hasil Clustering
Setelah melakukan validasi cluster, pemetaan dilakukan dengan 3 cluster. Pemetaan ini bermanfaat untuk melihat visualisasi hasil clustering SOM dalam bentuk peta, sehingga dapat mempermudah pemahaman cluster yang terbentuk secara visual.
Berdasarkan pemetaan pada Gambar 13, terlihat adanya pola pengelompokan geografis yang sangat jelas dan berkorelasi kuat dengan letak kewilayahan. Cluster 1 (Merah) tampak mendominasi wilayah barat dan tengah Indonesia, di mana sebagian besar provinsi di Pulau Sumatera dan Kalimantan, beserta beberapa provinsi di Sulawesi, termasuk di dalamnya. Sementara itu, Cluster 2 (Kuning) terkonsentrasi di Kawasan Timur Indonesia, mencakup provinsi-provinsi di Kepulauan Nusa Tenggara, Maluku, dan Papua.

Gambar 13 Pemetaan Cluster
Pola yang paling spesifik terlihat pada Cluster 3 (Hijau), yang secara eksklusif mengelompokkan provinsi-provinsi utama di Pulau Jawa. Peta ini secara visual menegaskan bahwa hasil pengelompokan SOM memiliki korelasi yang kuat dengan letak geografis, yang menunjukkan adanya pola kewilayahan yang nyata di Indonesia. Analisis lebih rinci mengenai karakteristik sosial-ekonomi yang mendefinisikan setiap cluster akan dibahas pada bagian selanjutnya.
6. Profilisasi Hasil Cluster
Tabel 9 Profilisasi Hasil Cluster
| Variabel | ||||
| Cluster 1 | Cluster 2 | Cluster 3 | ||
| PPM | 10.67 | 7,83 | 17,71 | 7,59 |
| TPT | 4,38 | 4,70 | 3,30 | 5,48 |
| IG | 0,3406 | 0,32 | 0,36 | 0,40 |
| AHH | 70,58 | 71,34 | 67,73 | 74,02 |
| RLS | 8,84 | 9,30 | 7,76 | 9,17 |
| PD | 7.178,1 | 5.133,13 | 1.172,76 | 35.451,48 |
Berdasarkan Tabel 9, profilisasi cluster yang menampilkan nilai rata-rata dari setiap variabel secara jelas mengungkap tiga profil atau “wajah” pembangunan yang berbeda dan unik di Indonesia. Kelompok pertama, Cluster 3, dapat diidentifikasi sebagai pusat perekonomian unggul. Cluster ini menonjol dengan kapasitas fiskal (Pajak Daerah) yang luar biasa besar, sekitar lima kali lipat dari rata-rata nasional, serta memiliki Angka Harapan Hidup (AHH) tertinggi. Namun, keunggulan ini disertai tantangan berupa Tingkat Pengangguran Terbuka (TPT) dan ketimpangan (Indeks Gini) yang juga paling tinggi, yang merupakan ciri khas wilayah urban dan industrial yang dinamis.
Selanjutnya, Cluster 1 merupakan kelompok terbesar yang mewakili wilayah menengah-maju yang stabil. Kelompok ini secara konsisten menunjukkan kondisi yang lebih baik dari rata-rata nasional pada berbagai indikator sosial, dengan tingkat kemiskinan dan ketimpangan yang lebih rendah serta Rata-rata Lama Sekolah (RLS) yang tertinggi di antara semua cluster. Kapasitas fiskalnya, meskipun di bawah rata-rata nasional, masih jauh lebih kuat dibandingkan kelompok berikutnya.
Terakhir, Cluster 2 secara jelas mengelompokkan provinsi-provinsi yang menghadapi tantangan pembangunan paling signifikan. Kelompok ini ditandai oleh persentase penduduk miskin yang tertinggi, AHH dan RLS yang terendah, serta kapasitas fiskal yang paling terbatas. Anomali TPT yang rendah pada kelompok ini kemungkinan besar mencerminkan dominasi sektor informal atau pertanian, bukan pasar kerja formal yang sehat.
Secara keseluruhan, hasil ini menegaskan adanya tiga wajah pembangunan di Indonesia: kelompok pusat ekonomi yang maju namun timpang (Cluster 3), kelompok menengah-maju yang stabil dan merata sebagai tulang punggung nasional (Cluster 1), serta kelompok tertinggal yang memerlukan intervensi kebijakan yang kuat untuk mengatasi berbagai keterbatasan mendasar (Cluster 2).
Tabel 10 Karakteristik Cluster Berdasarkan Rata-rata
| Cluster | PPM | TPT | IG | AHH | RLS | PD |
| 1 | – | + | – | + | + | – |
| 2 | + | – | + | – | – | – |
| 3 | – | + | + | + | + | + |
Tabel 10 menyajikan ringkasan profil dari tiga cluster optimal, yang secara efektif merangkum tiga profil pembangunan yang berbeda di Indonesia. Cluster 3, merepresentasikan kelompok provinsi maju yang dinamis. Keunggulannya terlihat pada hampir semua indikator positif seperti kapasitas fiskal dan Angka Harapan Hidup. Namun, kemajuan ini diiringi tantangan khas wilayah urban berupa Tingkat Pengangguran Terbuka dan ketimpangan yang juga tinggi. Berbeda dengan itu, Cluster 1 menunjukkan profil kelompok menengah-maju yang stabil. Pada kelompok ini, tingkat kemiskinan dan ketimpangan berada di bawah rata-rata, sementara capaian pendidikan dan kesehatan tergolong baik.
Cluster 2, secara jelas menggambarkan kelompok provinsi tertinggal yang menghadapi tantangan multidimensi. Hampir semua indikator kesejahteraan, kualitas sumber daya manusia, dan kapasitas ekonominya berada di bawah rata-rata nasional. Secara keseluruhan, ringkasan ini secara definitif menegaskan bahwa tiga cluster yang terbentuk memberikan gambaran yang jelas dan valid mengenai adanya tiga kelompok provinsi dengan karakteristik yang sangat berbeda di Indonesia: maju (Cluster 3), menengah (Cluster 1), dan tertinggal (Cluster 2).
KESIMPULAN
Riset ini bertujuan menelusuri profil kesejahteraan provinsi di Indonesia berdasarkan realisasi pajak daerah dengan menggunakan metode Self-Organizing Maps (SOM) untuk mengidentifikasi pola dan karakteristik ekonomi antarwilayah.
Hasil pengelompokan secara jelas menunjukkan adanya tiga profil atau “wajah” pembangunan yang berbeda dan memiliki pola geografis yang koheren:
- Cluster 3 (Maju): Terdiri dari 4 provinsi pusat perekonomian di Pulau Jawa, cluster ini memiliki karakteristik kapasitas fiskal yang sangat unggul dan indikator pembangunan manusia yang tinggi. Namun, keunggulan ini disertai dengan tantangan berupa tingkat pengangguran dan ketimpangan yang juga tertinggi.
- Cluster 1 (Menengah): Merupakan kelompok terbesar yang beranggotakan 23 provinsi, cluster ini menjadi representasi wilayah menengah-maju yang stabil. Profilnya ditandai dengan kondisi sosial yang lebih baik dari rata-rata nasional, seperti tingkat kemiskinan dan ketimpangan yang rendah serta capaian pendidikan yang tinggi, meskipun kapasitas fiskalnya tidak sebesar cluster maju.
- Cluster 2 (Tertinggal): Terdiri dari 11 provinsi yang mayoritas berada di Kawasan Timur Indonesia, cluster ini menghadapi tantangan pembangunan yang multidimensi. Profilnya ditandai oleh tingkat kemiskinan tertinggi, kualitas sumber daya manusia (kesehatan dan pendidikan) terendah, serta kapasitas fiskal yang sangat terbatas.
Penelitian ini menegaskan bahwa kapasitas fiskal (Pajak Daerah) merupakan salah satu pembeda utama antar cluster, namun kesejahteraan adalah sebuah konsep multidimensi. Temuan ini mengimplikasikan bahwa pendekatan pembangunan “satu ukuran untuk semua” tidak lagi relevan. Diperlukan kebijakan yang dirancang secara spesifik sesuai dengan karakteristik unik dari masing-masing cluster untuk mendorong pembangunan yang lebih merata dan berkeadilan di seluruh Indonesia.
KETERBATASAN
Penelitian ini memiliki beberapa keterbatasan yang perlu diakui dan dapat menjadi dasar untuk perbaikan di masa mendatang atau untuk penelitian selanjutnya:
- Data Lintas-Seksi (Cross-Sectional): Penggunaan data hanya pada satu periode waktu (tahun 2024) memberikan gambaran yang statis. Keterbatasan ini membuat penelitian tidak dapat menganalisis dinamika atau perubahan profil cluster dari waktu ke waktu.
- Agregasi di Tingkat Provinsi: Analisis dilakukan pada level provinsi, sehingga mengasumsikan bahwa setiap provinsi bersifat homogen. Hal ini dapat menutupi adanya ketimpangan pembangunan yang signifikan di dalam suatu provinsi (antara kabupaten/kota).
- Keterbatasan Variabel: Meskipun enam variabel yang digunakan sudah cukup representatif, masih terdapat faktor-faktor lain yang memengaruhi kesejahteraan dan tidak disertakan, seperti kualitas tata kelola pemerintahan, tingkat digitalisasi, kualitas lingkungan hidup, atau kontribusi sektor ekonomi tertentu (misalnya pariwisata atau pertambangan).
SARAN
Berdasarkan keterbatasan tersebut, beberapa arah penelitian lanjutan yang dapat dikembangkan adalah:
- Menggunakan Data Panel: Penelitian selanjutnya dapat menggunakan data panel (multi-provinsi, multi-tahun) untuk menganalisis mobilitas atau pergerakan provinsi antar cluster dari tahun ke tahun. Ini akan membantu mengidentifikasi faktor-faktor pendorong keberhasilan atau kegagalan suatu daerah dalam meningkatkan kesejahteraannya.
- Analisis di Level Kabupaten/Kota: Melakukan analisis serupa di tingkat kabupaten/kota akan memberikan gambaran yang lebih granular mengenai kantong-kantong kemiskinan atau kemajuan di dalam provinsi, sehingga rekomendasi kebijakan bisa lebih tepat sasaran.
- Menambah Variabel Penelitian: Memperkaya model dengan variabel lain seperti Indeks Demokrasi Indonesia (IDI), kualitas infrastruktur, atau Indeks Pembangunan Teknologi Informasi dan Komunikasi (IP-TIK) dapat memberikan pemahaman yang lebih komprehensif mengenai faktor-faktor yang membentuk profil kesejahteraan daerah.
- Analisis Kausalitas: Setelah pola pengelompokan teridentifikasi, penelitian selanjutnya dapat menggunakan model ekonometrika (seperti analisis regresi) untuk menguji hubungan kausalitas antara variabel-variabel tertentu (misalnya, belanja modal pemerintah terhadap penurunan kemiskinan) yang spesifik untuk setiap profil cluster.
DAFTAR PUSTAKA
Angkat, S. S., & Saharuddin, S. (2023). Pengaruh Indeks Gini Rasio, Indeks Kemahalan Konstruksi, Pengeluaran Perkapita terhadap Indeks Pembangunan Manusia (IPM). Jurnal Ekonomi Regional Unimal, 6(2), 13–21.
Annam, M. M., & Nasir, M. S. (2023). Analisis faktor yang mempengaruhi tingkat pengangguran terbuka di Provinsi Banten 2018–2022. JIDE: Journal of International Development Economics, 2(1), 1–20.
Arofah, I., & Rohimah, S. (2019). Analisis jalur untuk pengaruh angka harapan hidup, harapan lama sekolah, rata-rata lama sekolah terhadap indeks pembangunan manusia melalui pengeluaran riil per kapita di Provinsi Nusa Tenggara Timur. Jurnal Saintika Unpam: Jurnal Sains dan Matematika Unpam, 2(1), 76.
Arno, N. F., & Ahsan, M. (2017). Clustering data mahasiswa menggunakan metode Self Organizing Maps untuk menentukan strategi promosi Universitas Kanjuruhan Malang. BIMASAKTI: Jurnal Riset Mahasiswa Bidang Teknologi Informasi, 1–10.
Badan Pusat Statistik. (2018). Rata-rata Lama Sekolah Kabupaten Kotawaringin Barat. Badan Pusat Statistik Kabupaten Kotawaringin Barat.
Badan Pusat Statistik. (2017). Indeks Pembangunan Manusia Kabupaten Tanjung Jabung Timur 2012–2016. Badan Pusat Statistik.
Damayanti, Y., & Ratnasari, V. (2020). Pemodelan penduduk miskin di Jawa Timur menggunakan metode Geographically Weighted Regression (GWR). Jurnal Sains dan Seni ITS, 9(2), A123–A128.
Effendi, S. (2002). Pembangunan dan permasalahan kemiskinan di Indonesia. UI Press.
Febriani, V., & Mildawati, T. (2021). Pengaruh pajak daerah dan retribusi daerah terhadap belanja daerah Kota Surabaya. Jurnal Ilmu dan Riset Akuntansi (JIRA), 10(1).
Taufiq, I., Darmanto, & Utami, W. B. (2023). Pengaruh pajak daerah, retribusi daerah, dan dana perimbangan terhadap belanja modal di Provinsi Jawa Barat tahun 2020–2022. Jurnal Ilmiah Keuangan Akuntansi Bisnis, 404–411.