

PENDAHULUAN
Kepercayaan publik terhadap institusi penegak hukum merupakan asas utama dalam tegaknya supremasi hukum di suatu negara demokrasi. Indonesia sebagai negara hukum sebagaimana tertuang dalam Pasal 1 ayat (3) Undang-Undang Dasar Negara Republik Indonesia Tahun 1945 menempatkan hukum sebagai aturan yang berlaku adil bagi seluruh warga tanpa membedakan status sosial, kondisi ekonomi, maupun kedekatan politik seseorang (Man thovani, 2019). Namun demikian, penegakan hukum di Indonesia masih dihadapkan pada berbagai persoalan struktural yang mengakar di dalam tubuh institusi penegak hukum itu sendiri (Firmansyah & Pangestika, 2025).
Hasil survei Lembaga Survei Indonesia pada periode 31 Maret–4 April 2023 menunjukkan bahwa tingkat kepercayaan publik terhadap lembaga penegak hukum masih bervariasi. Kepolisian menempati posisi dengan tingkat kepercayaan paling rendah dibandingkan lembaga lainnya, yaitu sebesar 60%. Angka ini berada di bawah Kejaksaan Agung yang mencapai 72% serta Komisi Pemberantasan Korupsi (KPK) sebesar 66% (Lembaga Survei Indonesia, 2023). Situasi ini semakin diperburuk oleh berbagai peristiwa yang mendapat sorotan luas dari publik dalam beberapa waktu terakhir. Krisis kepercayaan publik terhadap kepolisian semakin menguat seiring dengan masifnya pemberitaan mengenai berbagai kasus pelanggaran hukum yang dilakukan oleh aparat penegak hukum. Ketika aparatur negara yang seharusnya menjadi pelindung dan pengayom masyarakat justru menjadi aktor pelanggaran, reaksi publik yang muncul berkembang menjadi sentimen kolektif di ruang digital. Media sosial berperan penting sebagai arena pembentukan opini publik, ekspresi emosional, serta mobilisasi kritik sosial terhadap aparatur negara (Valentino et al., 2025). Berbagai penelitian menunjukkan bahwa media sosial telah menggeser paradigma komunikasi publik dari yang semula bersifat satu arah menjadi percakapan multiarah yang terbuka dan sulit dikendalikan oleh kekuatan institusional mana pun (Chadwick & Vaccari, 2019). Sehingga diperlukan analisis sentimen terhadap krisis akuntabilitas aparat dan responsivitas pemerintah dengan mengklasifikasikan apakah opini publik tersebut tergolong positif, netral, atau negatif. Analisis sentimen merupakan salah satu cabang Natural Language Processing (NLP) yang bertujuan untuk mengidentifikasi, mengekstraksi, dan mengkuantifikasi orientasi opini atau emosi dari teks secara otomatis. Hal ini tidak hanya berguna untuk memetakan kecenderungan opini masyarakat, tetapi juga untuk mengevaluasi efektivitas respons pemerintah terhadap isu-isu yang berkembang.
Penelitian ini menempatkan empat kasus viral di aplikasi TikTok sebagai objek analisis sentimen yang mencerminkan spektrum respons publik terhadap isu krisis akuntabilitas aparat dan responsivitas pemerintah, yaitu:
- Penganiayaan oleh anggota Brimob yang mengakibatkan kematian pelajar di Tual, Maluku. Bripda Masias Siahaya (MS), anggota Satuan Brimob Polda Maluku, resmi dikenakan sanksi Pemberhentian Tidak Dengan Hormat (PTDH) setelah melakukan penganiayaan terhadap AT (14), pelajar Madrasah Tsanawiyah Negeri Kota Tual, menggunakan helm hingga korban meninggal dunia (Liputan6.com, 2026). Kasus ini menyentuh setidaknya dua lapisan hukum secara bersamaan yakni hukum pidana umum dan hukum perlindungan anak. Tindakan kekerasan aparat yang berujung pada kematian seseorang tanpa melalui prosedur hukum yang sah dikategorikan sebagai extrajudicial killing, yang berdasarkan Penjelasan Pasal 104 ayat (1) Undang-Undang Nomor 39 Tahun 1999 tentang Hak Asasi Manusia merupakan pelanggaran HAM berat (Munir et al., 2022).
- Dua anggota Polri, Nabil Ijlal Fadlul Rahman dan Samson Pardamean, dinyatakan terbukti melakukan pelanggaran berat dan perbuatan tercela setelah terlibat dalam kasus pemerkosaan terhadap seorang remaja putri berusia 18 tahun berinisial C (Deadline.co.id, 2026). Keduanya menjalani sidang Komisi Kode Etik Polri (KKEP) dan dijatuhi Pemberhentian Tidak Dengan Hormat (PTDH) pada 6 Februari 2026.
- Penjual es kue dituduh menggunakan bahan spons di Kemayoran, Jakarta. Sudrajat (50) mengalami nasib nahas saat berjualan es kue di wilayah Utan Panjang, Kemayoran, Jakarta Pusat (Liputan6.com, 2026). Selain dituduh menjual makanan berbahan spons, ia mengaku mendapatkan penganiayaan dari anggota TNI dan Polri. Ia mengaku dikepung, dipukul menggunakan batu cincin, disabet selang, dan ditendang. Hasil pemeriksaan Tim Keamanan Pangan Dokpol Polda Metro Jaya kemudian menyimpulkan bahwa es gabus yang dijualnya tidak mengandung bahan berbahaya. Kasus ini melibatkan dua pelanggaran hukum yang saling berlapis yakni tindak kekerasan fisik dan penyalahgunaan kewenangan aparat.
- Penembakan oleh polisi terhadap pemain senjata jelly di Makassar. Peristiwa bermula saat ada laporan terkait sekelompok remaja yang bermain tembak-tembakan menggunakan senjata jenis Omega yang meresahkan warga pengguna Jalan Toddopuli, Makassar (Tvonenews.com, 2026). Iptu N, Kanit Reskrim Polsek Panakukang, melakukan penangkapan sambil melepaskan tembakan peringatan. Saat korban berusaha memberontak, tiba-tiba terdengar letusan senjata tanpa sengaja dari senjata Iptu N. Korban, Bertrand Eka Prasetyo (18), tidak dapat diselamatkan meski sudah mendapatkan penanganan medis di rumah sakit.
Dalam upaya menganalisis sentimen dari data teks informal di media sosial, pendekatan deep learning berbasis arsitektur Long Short-Term Memory (LSTM) dan pengembangannya, yaitu Bidirectional Long Short-Term Memory (BiLSTM), terbukti lebih unggul dibandingkan metode machine learning seperti Naïve Bayes, Support Vector Machine (SVM), maupun pendekatan berbasis leksikon (Suhaeni et al., 2024). Arsitektur BiLSTM memperluas kemampuan LSTM dengan memproses data teks dalam dua arah secara simultan, yaitu dari kiri ke kanan (forward) dan dari kanan ke kiri (backward) (Anugra M. et al., 2024). Sejumlah penelitian terdahulu telah menunjukkan bahwa metode BiLSTM efektif dalam menganalisis berbagai isu sosial di Indonesia. Studi mengenai sentimen terhadap Undang-Undang Cipta Kerja mampu mencapai tingkat akurasi sebesar 83,22% (Anugra M. et al., 2024). Sementara itu, analisis terhadap isu korupsi dana bencana juga memperlihatkan kemampuan BiLSTM dalam mengidentifikasi dominasi sentimen negatif secara akurat (Prabowo, T. et al., 2026). Temuan-temuan ini memperkuat relevansi penggunaan BiLSTM dalam penelitian yang berfokus pada isu krisis akuntabilitas aparat dan responsivitas pemerintah.
Berdasarkan permasalahan yang telah diidentifikasi serta berbagai penelitian terdahulu yang telah dipaparkan, masih terdapat sejumlah celah yang perlu diperhatikan dan diatasi, seperti: (1) belum ada kajian yang secara spesifik menganalisis sentimen kolektif masyarakat terhadap pelanggaran aparat dan ketidakadilan hukum dengan memanfaatkan data komentar TikTok di Indonesia; dan (2) sebagian besar penelitian sebelumnya berfokus pada platform seperti X (Twitter) dan YouTube, sementara TikTok sebagai platform dengan pertumbuhan pengguna yang sangat pesat masih relatif kurang dieksplorasi.
Oleh karena itu, penelitian ini bertujuan untuk: (1) menganalisis distribusi dan pola sentimen kolektif masyarakat Indonesia terhadap isu-isu krisis akuntabilitas aparat dan responsivitas pemerintah melalui data komentar TikTok; (2) mengidentifikasi tema-tema yang mencerminkan persepsi publik terhadap responsivitas pemerintah dalam merespons kasus-kasus pelanggaran aparat; (3) membangun dan mengevaluasi model klasifikasi sentimen berbasis arsitektur BiLSTM yang mampu mengklasifikasikan teks komentar informal berbahasa Indonesia dengan akurasi tinggi; dan (4) memberikan kontribusi berbasis data terhadap pemahaman tentang dinamika kepercayaan publik terhadap institusi kepolisian dan sistem hukum Indonesia, sebagai masukan bagi pengembangan kebijakan komunikasi publik yang lebih responsif dan akuntabel.
METODOLOGI
1. Pengumpulan Data
Data utama penelitian ini adalah komentar pengguna TikTok yang dikumpulkan melalui teknik web scraping menggunakan layanan Apify Client. Pendekatan pengumpulan data yang digunakan berbasis URL spesifik dari masing-masing postingan TikTok yang memuat konten terkait keempat isu krisis akuntabilitas aparat dan responsivitas pemerintah. Pilihan ini dikarenakan pengumpulan berbasis URL memastikan bahwa seluruh data bersumber dari konten yang menjadi fokus penelitian. Total data yang berhasil dikumpulkan dan diproses mencapai 3.532 komentar sebelum melalui tahapan seleksi dan pembersihan data, kemudian data disimpan ke dalam bentuk file dengan format CSV. Tabel 1 menampilkan ringkasan data hasil scraping pada penelitian ini.
Tabel 1. Ringkasan Scraping Data

2. Pra-pemrosesan Data
Prapemrosesan data merupakan proses mengubah serta membersihkan data agar tersusun dalam format yang lebih terstruktur. Prapemrosesan dalam penelitian ini mengikuti alur yang telah banyak digunakan dalam studi analisis teks berbahasa Indonesia, yakni cleaning, case folding, stopword removal, stemming, dan tokenizing.
- Cleaning: Penghapusan elemen non-informatif meliputi URL, tag HTML, mention pengguna (@username), tagar (#hashtag), karakter non-alfabet, serta normalisasi spasi berlebih.
- Case folding: Konversi seluruh karakter teks ke huruf kecil (lowercase) untuk memastikan konsistensi representasi leksikal.
- Stopword removal: Eliminasi kata-kata umum tidak bermakna menggunakan kamus stopword.
- Stemming: Proses reduksi kata ke bentuk dasarnya menggunakan pustaka PySastrawi.
- Tokenizing: Pemisahan teks menjadi token-token individual sebagai satuan analisis dasar.
3. Pelabelan Sentimen
Pelabelan data dilakukan secara otomatis menggunakan pendekatan berbasis leksikon sentimen. Pendekatan ini bekerja dengan membandingkan setiap token dalam teks terhadap daftar kata yang sudah diklasifikasikan sebagai positif, negatif, atau netral. Setiap teks yang telah melalui prapemrosesan diberi skor berdasarkan jumlah kemunculan kata positif dan negatif dari leksikon. Aturan pelabelan yang diterapkan adalah sebagai berikut:
- Jika jumlah kata positif lebih banyak dari negatif, teks diberi label positif.
- Jika jumlah kata negatif lebih banyak dari positif, teks diberi label negatif.
- Jika keduanya sama atau tidak ditemukan kata bermakna dari leksikon, teks diberi label netral.
Pendekatan ini mengacu pada metode yang dikembangkan oleh Liu (2015), di mana skor keseluruhan kata-kata dalam teks digunakan untuk menentukan orientasi sentimen.
- Penanganan Imbalance Data
Distribusi kelas yang tidak seimbang adalah masalah umum dalam dataset analisis sentimen. Ketidakseimbangan pada dataset membuat model bias ke kelas mayoritas, sehingga performa pada kelas minoritas menjadi buruk (He & Garcia, 2009). Penelitian ini menggunakan Random Oversampling untuk menangani masalah tersebut. Teknik ini bekerja dengan menduplikasi secara acak sampel dari kelas minoritas hingga distribusi kelas menjadi lebih seimbang. Berbeda dengan SMOTE yang menghasilkan data sintetis baru, Random Oversampling tidak menciptakan data baru, melainkan mengulang data yang sudah ada. Implementasinya dilakukan menggunakan pustaka imbalanced-learn dengan kelas RandomOverSampler. Setelah oversampling, jumlah sampel di setiap kelas disesuaikan agar proporsional atau mendekati distribusi yang seragam. Oversampling hanya diterapkan pada data latih, bukan pada data uji untuk menghindari data leakage, yaitu kondisi di mana informasi dari data uji ikut mempengaruhi proses pelatihan model, yang dapat membuat evaluasi menjadi tidak valid.
4. Arsitektur Model
Model klasifikasi sentimen dikembangkan menggunakan arsitektur Bidirectional Long Short-Term Memory (BiLSTM) yang diimplementasikan dengan pendekatan Sequential berbasis TensorFlow. BiLSTM merupakan pengembangan dari LSTM yang mampu memproses data urutan teks dalam dua arah secara simultan, yaitu arah maju (forward) yang membaca token dari awal hingga akhir, serta arah mundur (backward) yang membaca token dari akhir ke awal (Mahadevaswamy & Swathi, 2023). BiLSTM sangat berguna dalam Natural Language Processing (NLP), termasuk analisis sentimen, karena kemampuannya menangani ketergantungan jangka panjang dengan memperkenalkan memori ke dalam model untuk menghasilkan prediksi yang lebih baik.
5. Evaluasi Model
Evaluasi kinerja model dilakukan menggunakan Confusion Matrix. Confusion Matrix merupakan salah satu alat evaluasi yang sangat penting untuk menilai kinerja model klasifikasi, termasuk pada analisis sentimen (Kolo & Supatman, 2024). Matriks ini terdiri atas enam komponen, yaitu True Negative (TN), False Negative (FN), True Neutral (TNt), False Neutral (FNt), True Positive (TP), dan False Positive (FP). True Negative (TN) menggambarkan jumlah kelas negatif yang diprediksi benar sebagai negatif, sementara False Negative (FN) menunjukkan jumlah data yang salah diprediksi sebagai kelas negatif. True Neutral (TNt) menunjukkan teks berlabel netral yang diprediksi dengan benar sebagai netral, adapun False Neutral (FNt) merupakan teks yang sebenarnya netral tetapi diprediksi ke kelas lain, atau sebaliknya teks dari kelas lain diprediksi sebagai netral. True Positive (TP) menunjukkan jumlah data yang berhasil diprediksi secara benar sebagai kelas positif, sedangkan False Positive (FP) adalah jumlah data yang keliru diprediksi sebagai kelas positif. (Anugra M. et al., 2024)
Tabel 2. Confusion Matrix
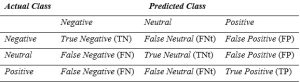
Berdasarkan nilai-nilai pda Confusion Matrix tersebut, berbagai metrik evaluasi dapat dihitung, seperti accuracy, precision, recall, dan F1-score. Keempat metrik ini memberikan gambaran mengenai kemampuan model dalam mengklasifikasikan sentimen secara tepat (Citra R et al., 2024).
Accuracy = TP + TN + TNt TP + TN + TNt + FP + FN + FNt (Anugra M. et al., 2024)
Precision = TP TP + FP (Anugra M. et al., 2024)
Recall = TP TP + FN + FNt (Anugra M. et al., 2024)
F1 – Score = 2 × Precision × Recall Precision + Recall (Anugra M. et al., 2024)
HASIL DAN PEMBAHASAN
1. Analisis Sentimen
a. Pra-Pemrosesan Data
Berdasarkan hasil pra-pemrosesan data, diperoleh sebanyak 3203 data teks yang telah melalui proses pembersihan dengan beberapa tahapan yaitu, cleaning, case folding, stopword removal, stemming, dan tokenizing dari total 3532 data awal. Hasil pra-pemrosesan data dapat dilihat pada table-tabel berikut.
Tabel 3. Contoh Hasil Cleaning

Tabel 4. Contoh Hasil Case Folding

Tabel 5. Contoh Hasil Stopword Removal

Tabel 6. Contoh Hasil Stemming

Tabel 7. Contoh Hasil Tokenizing

b. Pelabelan Sentimen
Selanjutnya dilakukan pelabelan sentimen berbasis leksikon. Berdasarkan hasil pelabelan, dataset untuk Krisis Akuntabilitas Aparat dan Responsivitas Pemerintah terdiri dari 2.081 data bersentimen negatif, 798 data bersentimen netral, dan 324 data bersentimen positif yang mencerminkan dominasi sentimen negatif yang signifikan dalam respons publik terhadap isu krisis akuntabilitas aparat dan responsivitas pemerintah. Dominasi sentimen negatif ini mengindikasikan bahwa opini publik terhadap topik yang dianalisis cenderung mengarah pada persepsi yang kurang baik atau mengandung kritik. Hasil pelabelan sentimen ditunjukkan pada Tabel 8.
Tabel 8. Label Data

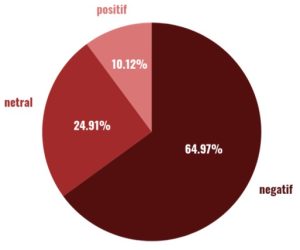
Gambar 1. Distribusi Awal Sentimen
Dominasi sentimen negatif yang diperoleh dalam penelitian ini menandakan adanya penurunan tingkat kepercayaan publik terhadap institusi penegak hukum, khususnya kepolisian. Temuan ini sejalan dengan hasil survei Lembaga Survei Indonesia (2023) yang menunjukkan bahwa tingkat kepercayaan terhadap kepolisian berada pada posisi yang lebih rendah dibandingkan lembaga penegak hukum lainnya. Prabowo, T. et al. (2026) dalam studinya tentang sentimen terhadap korupsi dana bencana menggunakan Bi-LSTM juga menemukan dominasi sentimen negatif yang serupa, mengindikasikan bahwa krisis kepercayaan publik terhadap institusi negara merupakan fenomena yang konsisten dan meluas di ruang digital Indonesia. Temuan ini sejalan pula dengan argumen Chadwick & Vaccari (2019) bahwa platform digital telah menjadi ruang ekspresi ketidakpuasan publik yang tidak dapat dibendung.
c.Visualisasi Wordcloud dan Frekuensi Kata
Analisis berikutnya dilakukan dengan melihat frekuensi kata pada masing-masing kategori sentimen. Pada kelas negatif, kata “polisi” menjadi kata paling dominan dengan selisih yang sangat jauh dibandingkan kata lainnya. Kata-kata berikutnya adalah “main”, “anak”, “pecat”, “tembak”, dan “senjata”. Kata “hukum”, “bahaya”, “korban”, dan “penjara” juga menempati posisi atas. Pola ini mengisyaratkan bahwa ekspresi negatif publik secara langsung terarah pada institusi kepolisian dan pada konsekuensi yang dianggap tidak sepadan, seperti pemecatan yang dinilai belum cukup atau hukuman yang tidak sebanding dengan tindak pidana yang dilakukan. Visualisasi sentimen negatif dapat dilihat pada Gambar 2.
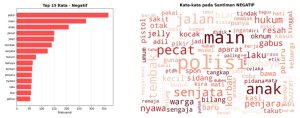
Gambar 2. Visualisasi Sentimen Negatif
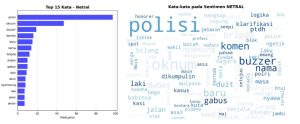
Pada kelas netral, kata “polisi”, “oknum”, dan “buzzer” mendominasi. Kemunculan kata “oknum” dapat diartikan bahwa terdapat pembeda antara aparat bermasalah secara individu dengan institusi kepolisian secara keseluruhan. Penggunaan istilah ini mencerminkan posisi netral yang berupaya membedakan kesalahan individual dari tanggung jawab di institusi. Selain itu, kemunculan kata “buzzer” mengindikasikan kesadaran publik terhadap kemungkinan adanya aktor yang mencoba mengendalikan narasi di kolom komentar. Visualisasi sentimen netral dapat dilihat pada Gambar 3.
Pada kelas positif, kata “lulus” menjadi kata paling dominan, diikuti “polisi”, “dukung”, dan “sekolah”. Kemunculan kata “lulus” dan “sekolah” berkaitan dengan isu pelajar yang menjadi korban dalam salah satu kasus, di mana publik mengungkapkan belasungkawa atau harapan atas nasib korban. Kata “dukung” mengindikasikan sebagian audiens yang memberikan dukungan terhadap tindakan pemecatan atau proses hukum yang berlangsung. Visualisasi sentimen positif dapat dilihat pada Gambar 4.
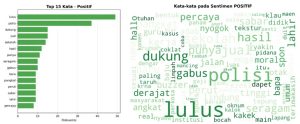
Gambar 4. Visualisasi Sentimen Positif
Selain itu, kemunculan kata “polisi” sebagai kata dengan frekuensi tinggi pada seluruh kelas sentimen menunjukkan bahwa opini publik tidak hanya berfokus pada individu pelaku, melainkan telah berkembang menjadi kritik terhadap institusi kepolisian secara keseluruhan.
2. Klasifikasi BiLST
a. Penanganan Imbalance Data
Sebelum pelatihan model, dilakukan penanganan ketidakseimbangan data menggunakan teknik Random Oversampling, sehingga jumlah data pada masing-masing kelas menjadi seimbang, yaitu 2081 data per kelas. Tujuannya adalah untuk menghindari bias model terhadap kelas mayoritas.
b. Pelatihan Model
Model klasifikasi sentimen dikembangkan menggunakan arsitektur Bidirectional Long Short-Term Memory (BiLSTM) berbasis TensorFlow. Sebelum masuk ke model, token hasil tokenizing dikonversi menjadi indeks numerik menggunakan Tokenizer dari Keras dengan ukuran kosakata 5.000 kata dan panjang sekuens maksimum 50 token, lalu diberi padding agar panjangnya seragam. Arsitektur model terdiri dari embedding layer berdimensi 64, Spatial Dropout sebesar 0,4, lapisan BiLSTM dengan 64 unit per arah yang menghasilkan representasi berdimensi 128 dilengkapi dropout 0,5, recurrent dropout 0,3, dan regularisasi L2, lapisan fully connected dengan 32 unit dan aktivasi ReLU, serta output layer dengan 3 neuron dan fungsi aktivasi softmax. Model dikompilasi menggunakan optimizer Adam dengan laju pembelajaran awal 0,0005 dan fungsi kerugian categorical crossentropy, dengan dua mekanisme callback yaitu Early Stopping dan Reduce Learning Rate on Plateau yang menurunkan laju pembelajaran sebesar 50% jika validation loss tidak membaik selama 3 epoch berturut-turut hingga batas minimum 1×10⁻⁶. Proses pelatihan dilakukan selama 30 epoch dapat dilihat pada Tabel 9.
Tabel 9. Perkembangan Akurasi dan Loss per Epoch selama Pelatihan
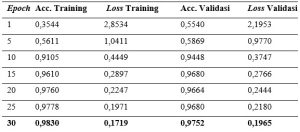
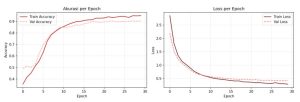
Gambar 5. Kurva Pelatihan
Berdasarkan Gambar 5, model menunjukkan peningkatan akurasi yang konsisten pada data latih, dari 35,44% pada epoch pertama menjadi 98,30% pada epoch ke-30. Akurasi validasi juga meningkat secara berkelanjutan dari 55,40% pada epoch pertama hingga mencapai 97,52% pada epoch ke-30. Penurunan nilai loss yang berlangsung stabil, disertai perbedaan yang kecil antara kurva training dan validation, menunjukkan bahwa penggunaan Spatial dropout efektif dalam menekan kemungkinan overfitting.
c. Evaluasi Model
Evaluasi kinerja model Bi-LSTM pada data uji dilakukan untuk mengukur kemampuan generalisasi model dalam mengklasifikasikan sentimen pada data yang tidak digunakan selama proses pelatihan. Hasil evaluasi menunjukkan bahwa model memiliki performa yang sangat baik dengan nilai accuracy sebesar 0,9672. Distribusi hasil klasifikasi disajikan pada Tabel 10.
Tabel 10. Confusion Matrix
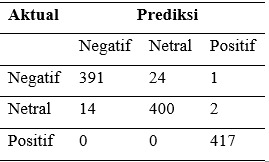
Berdasarkan Tabel 10 dapat diamati bahwa mayoritas data pada setiap kelas berhasil diklasifikasikan dengan benar. Pada kelas negatif, sebanyak 391 data berhasil diprediksi secara tepat, sementara sebagian kecil mengalami misklasifikasi ke kelas netral dan sangat sedikit ke kelas positif. Pada kelas netral, sebanyak 400 data berhasil dikenali dengan benar, sedangkan sebagian kecil lainnya keliru diklasifikasikan sebagai negatif maupun positif. Sementara itu, pada kelas positif, seluruh data berhasil diklasifikasikan dengan benar tanpa kesalahan prediksi.
Kinerja model pada masing-masing kelas selanjutnya dianalisis menggunakan metrik precision, recall, dan F1-score yang dirangkum pada Tabel 11.
Tabel 11. Hasil Evaluasi Model Bi-LSTM per Kelas Sentimen
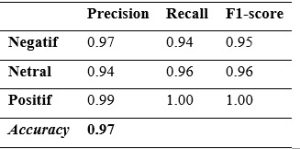
Berdasarkan Tabel 11, nilai precision yang tinggi pada kelas negatif menunjukkan bahwa prediksi negatif yang dihasilkan model sebagian besar sesuai dengan kondisi aktual, meskipun nilai recall yang sedikit lebih rendah mengindikasikan adanya sejumlah kecil data negatif yang tidak terdeteksi secara optimal. Pada kelas netral, nilai recall yang lebih tinggi dibandingkan precision menunjukkan bahwa model cukup sensitif dalam mendeteksi data netral. Sementara itu, kelas positif menunjukkan performa terbaik dengan nilai precision sebesar 0,99 dan recall mencapai 1,00, yang berarti seluruh data positif berhasil dikenali oleh model tanpa kesalahan.
3. Pembahasan
a. Implikasi Sosiopolitik
Dominasi sentimen negatif sebesar 64,97% yang ditemukan dalam data asli mencerminkan kerapuhan legitimasi institusional aparat penegak hukum di mata publik Indonesia. Keempat kasus yang menjadi objek penelitian secara kolektif membentuk narasi bahwa aparat penegak hukum tidak hanya gagal melindungi warga negara, tetapi juga aktif menjadi sumber ancaman dan ketidakadilan.
Temuan ini memiliki beberapa implikasi yang perlu mendapat perhatian serius. Pertama, tingginya volume komentar bersentimen negatif menunjukkan bahwa ruang digital, khususnya TikTok, telah menjadi arena ekspresi ketidakpuasan publik yang terbuka dan sulit dibendung. Ketika saluran pengaduan formal dianggap tidak responsif, masyarakat cenderung beralih ke platform digital sebagai media artikulasi kekecewaan mereka. Pola ini sejalan dengan argumen Chadwick & Vaccari (2019) bahwa platform digital telah menggeser struktur komunikasi publik dari yang semula satu arah menjadi percakapan multiarah yang berpotensi membentuk opini kolektif secara masif. Kedua, kemunculan kata “oknum” yang dominan pada kelas sentimen netral mengisyaratkan adanya strategi framing yang digunakan sebagian pengguna untuk memisahkan kesalahan individual dari tanggung jawab institusi. Ketiga, kemunculan kata “buzzer” dalam kelas sentimen netral mengindikasikan bahwa publik sudah cukup sadar terhadap kemungkinan adanya upaya manipulasi narasi di ruang digital. Kesadaran ini justru memperkuat skeptisisme publik terhadap respons resmi pemerintah dan institusi terkait, sehingga setiap pernyataan atau tindakan korektif yang dilakukan otoritas berpotensi diterima dengan kecurigaan, bukan kepercayaan. Keempat, perlu dicatat bahwa sentimen positif yang muncul dalam penelitian ini tidak sepenuhnya mencerminkan dukungan terhadap institusi kepolisian. Sebagian besar ekspresi positif justru berkaitan dengan ungkapan belasungkawa kepada korban dan dukungan atas proses pemecatan pelaku. Artinya, apresiasi publik bukan ditujukan kepada institusi, melainkan kepada tindakan korektif yang dianggap seharusnya sudah dilakukan jauh lebih awal.
Kondisi ini, apabila tidak direspons secara serius melalui reformasi institusional dapat berpotensi memperparah tergerusnya kepercayaan publik yang pada akhirnya dapat melemahkan legitimasi demokratis negara secara keseluruhan.
b. Keterbatasan Penelitian
Penelitian ini memiliki beberapa keterbatasan yang perlu diperhatikan.
- Data penelitian hanya berasal dari komentar TikTok pada empat kasus viral yang dipilih berdasarkan URL tertentu. Oleh karena itu, hasil penelitian ini belum dapat digeneralisasikan sebagai representasi menyeluruh dari opini publik Indonesia terhadap institusi penegak hukum. Data media sosial memiliki potensi bias karena karakter pengguna, algoritma platform, pola interaksi, serta cara platform menyimpan dan menampilkan data dapat memengaruhi informasi yang berhasil dikumpulkan (Ruths & Pfeffer, 2014).
- Penelitian ini menggunakan komentar teks sebagai satu-satunya sumber data. Padahal, TikTok merupakan platform multimodal yang memuat video, audio, caption, ekspresi visual, dan konteks percakapan yang dapat memengaruhi makna sentimen. Analisis sentimen media sosial juga menghadapi tantangan berupa bahasa informal, slang, emoji, sarkasme, ironi, konteks yang terfragmentasi, serta noise data seperti akun promosi atau bot (Nip, 2024). Dengan demikian, hasil klasifikasi sentimen dalam penelitian ini belum sepenuhnya menangkap kompleksitas ekspresi publik di TikTok.
- Pelabelan sentimen dilakukan secara otomatis menggunakan pendekatan berbasis leksikon. Pendekatan ini membantu proses pelabelan dalam jumlah besar, tetapi masih terbatas dalam mengenali konteks, negasi, sarkasme, ironi, dan makna implisit dalam komentar pendek. Keterbatasan ini penting karena keandalan label sangat memengaruhi kualitas model klasifikasi yang dilatih. Penelitian sentimen yang kuat sebaiknya tetap mempertimbangkan anotasi manual dan pengukuran kesepakatan antar-anotator untuk menilai reliabilitas label (Bobicev & Sokolova, 2017).
- Penelitian ini menangani ketidakseimbangan kelas dengan Random Oversampling. Teknik ini berguna untuk menyeimbangkan distribusi kelas, tetapi bekerja dengan menduplikasi sampel kelas minoritas. Duplikasi sampel dapat membuat model terlalu banyak mempelajari pola tertentu pada data latih dan berpotensi meningkatkan risiko overfitting, terutama ketika jumlah data awal pada kelas positif relatif kecil (Yu et al., 2021). Oleh karena itu, performa model yang tinggi perlu dibaca secara hati-hati karena belum diuji pada dataset eksternal yang benar-benar berbeda.
- Penelitian ini belum melakukan validasi lintas-platform, lintas-periode, atau lintas-kasus. Model diuji pada data yang berasal dari konteks isu yang sama, sehingga kemampuan generalisasi model terhadap isu lain, periode lain, atau platform lain seperti X, YouTube, dan Instagram belum dapat dipastikan. Selain itu, penelitian ini belum menguji metode pembanding berbasis transformer seperti IndoBERT yang dikembangkan khusus untuk pemrosesan bahasa Indonesia (Koto et al., 2020).
c. Saran
Penelitian selanjutnya disarankan untuk memperluas sumber data dengan memasukkan lebih banyak kasus, periode waktu yang lebih panjang, serta platform media sosial lain seperti X, YouTube, Instagram, dan Facebook. Perluasan data dapat membantu menguji apakah dominasi sentimen negatif terhadap isu akuntabilitas aparat bersifat konsisten atau hanya kuat pada kasus dan platform tertentu. Selain itu, analisis temporal dapat digunakan untuk melihat perubahan sentimen sebelum, selama, dan setelah respons resmi pemerintah atau institusi kepolisian.
Penelitian berikutnya juga perlu mengombinasikan pelabelan berbasis leksikon dengan anotasi manual oleh lebih dari satu anotator. Proses ini dapat dilengkapi dengan pengukuran inter-annotator agreement, seperti Cohen’s Kappa, agar reliabilitas label lebih terukur. Langkah ini penting karena komentar media sosial sering mengandung sarkasme, bahasa daerah, singkatan, dan ekspresi emosional yang sulit dibaca secara tepat oleh kamus sentimen otomatis.
Dari sisi pengembangan model, penelitian selanjutnya dapat membandingkan BiLSTM dengan beberapa metode lain, seperti CNN-LSTM, GRU, IndoBERT, multilingual BERT, atau model transformer lain yang telah dilatih pada korpus bahasa Indonesia. Perbandingan ini penting agar klaim performa model tidak hanya didasarkan pada satu arsitektur. Selain akurasi, evaluasi juga sebaiknya menampilkan macro-F1, weighted-F1, serta pengujian pada dataset eksternal.
Penelitian selanjutnya dapat menggunakan teknik penanganan imbalance data yang lebih beragam. Selain Random Oversampling, peneliti dapat menguji class weighting, focal loss, SMOTE, ADASYN, atau kombinasi oversampling dan undersampling. Pengujian beberapa teknik tersebut dapat membantu melihat apakah performa model tetap stabil tanpa terlalu bergantung pada duplikasi data kelas minoritas.
Dari sisi substansi, penelitian berikutnya disarankan untuk mengembangkan analisis berbasis aspek atau aspect-based sentiment analysis. Analisis ini dapat memisahkan sentimen publik terhadap beberapa aspek, misalnya pelaku aparat, institusi kepolisian, korban, sanksi hukum, respons pemerintah, dan proses keadilan. Pendekatan ini akan memberi gambaran yang lebih tajam dibandingkan klasifikasi umum positif, netral, dan negatif.
4. Kesimpulan
Penelitian ini berhasil membangun model klasifikasi sentimen berbasis BiLSTM untuk menganalisis opini publik terhadap isu krisis akuntabilitas aparat dan ketidakadilan hukum dari data komentar TikTok berbahasa Indonesia. Beberapa kesimpulan utama dapat ditarik dari penelitian ini.
- Model BiLSTM yang dikembangkan menunjukkan performa yang sangat baik dengan akurasi sebesar 96,72% pada data uji. Nilai F1-score per kelas juga tinggi, yaitu 0,95 untuk kelas negatif, 0,96 untuk kelas netral, dan 1,00 untuk kelas positif. Hasil ini membuktikan bahwa arsitektur BiLSTM mampu menangkap konteks linguistik teks informal berbahasa Indonesia secara efektif, termasuk ekspresi yang mengandung slang, singkatan, dan variasi ejaan yang umum ditemukan di platform media sosial.
- Dari sisi distribusi sentimen, data menunjukkan bahwa 64,97% komentar bersentimen negatif, 24,92% netral, dan hanya 10,12% positif. Pola ini mencerminkan kekecewaan publik yang dalam terhadap institusi penegak hukum, khususnya kepolisian. Analisis frekuensi kata memperkuat temuan ini, di mana kata “polisi” mendominasi seluruh kelas sentimen, menandakan bahwa kritik publik tidak lagi terbatas pada individu pelaku, melainkan telah berkembang menjadi evaluasi terhadap institusi secara keseluruhan.
Temuan-temuan ini diharapkan dapat menjadi masukan bagi pengembangan kebijakan publik yang lebih responsif, serta mendorong reformasi institusional yang berbasis pada pemantauan opini publik secara real-time.
Tim Penulis:
Patonangi M., Muh. Imam Bukhari, Haura Insiyah Bahar, Rizqiyah Khair Suyuti, Putri Anandita
DAFTAR PUSTAKA
Anugra, M., & Munawar. (2024). Sentiment analysis related to Law No. 6 of 2023 on the employment cluster using the bidirectional long short-term memory algorithm. Jurnal Komputer, Informasi dan Teknologi, 4(2), 1–14. https://doi.org/10.53697/jkomitek.v4i2.2051
Bobicev, V., & Sokolova, M. (2017). Inter-annotator agreement in sentiment analysis: Machine learning perspective. Proceedings of RANLP 2017, 97–102.
Chadwick, A., & Vaccari, C. (2019). Digital media, power, and democracy: The impact of social platforms on political communication. Journal of Communication, 69(2), 212–238.
Citra R, F., Indriyani, F., & Rahadjeng, I. R. (2024). Klasifikasi Tumor Otak Berbasis Magnetic Resonance Imaging Menggunakan Algoritma Convolutional Neural Network. Digital Transformation Technology, 3(2), 918–924. https://doi.org/10.47709/digitech.v3i2.3469
Deadline.co.id. (2026). Calon polwan diperkosa di Jambi, 2 polisi dipecat. Diakses pada 21 April 2026, dari https://deadline.co.id/calon-polwan-diperkosa-di-jambi-2-polisi-dipecat/
Firmansyah, D. D., & Pangestika, E. Q. (2025). Ketidakadilan dalam Penegakan Hukum di Indonesia: Sebuah Tinjauan Kritis. Jurnal Pustaka Cendekia Hukum dan Ilmu Sosial, 2(3), 219–223.
Kolo, S. Y., & Supatman, S. (2024). Analisis sentimen terhadap opini masyarakat terkait perubahan cuaca di Indonesia menggunakan algoritma support vector machine. JATI (Jurnal Mahasiswa Teknik Informatika), 8(2). https://doi.org/10.36040/jati.v8i2.8988
Koto, F., Rahimi, A., Lau, J. H., & Baldwin, T. (2020). IndoLEM and IndoBERT: A benchmark dataset and pre-trained language model for Indonesian NLP. Proceedings of COLING 2020, 757–770.
Lembaga Survei Indonesia. (2023). Rilis survei: Kepercayaan publik terhadap lembaga penegakan hukum, isu Piala Dunia U-20, aliran dana tak wajar di Kemenkeu, dugaan korupsi BTS, dan peta politik terkini. Diakses pada 21 April 2026, dari https://www.lsi.or.id/post/rilis-survei-lsi-09-april-2023
Liputan6.com. (2026). Anggota Brimob aniaya pelajar hingga tewas di Tual Maluku dipecat dari Polri. Diakses pada 21 April 2026, dari https://www.liputan6.com/news/read/6284699/anggota-brimob-aniaya-pelajar-hingga-tewas-di-tual-maluku-dipecat-dari-polri
Liputan6.com. (2026). Pengakuan pedagang es kue jadul yang dituduh berbahan spons: Saya dikepung, ditonjok. Diakses pada 21 April 2026, dari https://www.liputan6.com/news/read/6266169/pengakuan-pedagang-es-kue-jadul-yang-dituduh-berbahan-spons-saya-dikepung-ditonjok
Liu, B. (2015). Sentiment analysis: Mining opinions, sentiments, and emotions. Cambridge University Press.
Mahadevaswamy, U. B., & Swathi, P. (2023). Sentiment Analysis using Bidirectional LSTM Network. Procedia Computer Science, 218, 45–56. https://doi.org/10.1016/j.procs.2022.12.400
Manthovani, R. (2019). Kontribusi Kejaksaan RI untuk Konsep Bela Negara terhadap Perlindungan Masyarakat. Jurnal Hukum Universitas Pancasila, IV(2), 28–47.
Munir, A. S., Saputri, B. E., & Rachma, S. A. (2022). Extrajudicial Killing: Pelanggaran Hak atas Hidup dan Kaitannya dengan Asas Praduga Tak Bersalah. Rewang Rencang: Jurnal Hukum Lex Generalis, 3(12), 953–968.
Nip, J. Y. M. (2024). Social media sentiment analysis. Encyclopedia, 4(4), 1591–1603.
Prabowo, T., Muhammad Irfan Sarif, Sebayang, A., Ferdillah, T. D., & Muhammad Azuan. (2026). Analisis Sentimen Masyarakat terhadap Isu Korupsi Dana Bencana di Indonesia Menggunakan Metode Bidirectional Long Short-Term Memory (BiLSTM). Jurnal Komputer Teknologi Informasi Sistem Komputer (JUKTISI), 4(3), 1787–1795. https://doi.org/10.62712/juktisi.v4i3.756
Ruths, D., & Pfeffer, J. (2014). Social media for large studies of behavior. Science, 346(6213), 1063–1064.
Suhaeni, C., Wijayanto, H., & Kurnia, A. (2024). Sentiment Classification on the 2024 Indonesian Presidential Candidate Dataset Using Deep learning Approaches. Indonesian Journal of Statistics and Its Applications. https://doi.org/10.29244/ijsa.v8i2p83-94
Tvonenews.com. (2026). Remaja tewas ditembak Iptu N usai tawuran pakai senjata water jelly di Makassar, polisi masih tunggu hasil autopsi. Diakses pada 21 April 2026, dari https://www.tvonenews.com/berita/nasional/421230-remaja-tewas-ditembak-iptu-n-usai-tawuran-pakai-senjata-water-jelly-di-makassar-polisi-masih-tunggu-hasil-autopsi
Undang-Undang Dasar Negara Republik Indonesia Tahun 1945. Pasal 1 Ayat (3). Tentang Negara Hukum.
Undang-Undang Nomor 39 Tahun 1999 tentang Hak Asasi Manusia. Penjelasan Pasal 104 Ayat (1). Sekretariat Negara Republik Indonesia.
Valentino, A. A. R., Hasan, Pratama, V. A. P., & Misidawati, D. N. (2025). Analisis Sentimen Pengguna X terhadap Pengesahan KUHAP Terbaru. Jurnal Multidisiplin Ilmu Akademik (JMIA), 2(6), 896–902. https://doi.org/10.61722/jmia.v2i6.7341
Yu, L., Zhou, R., Chen, R., & Lai, K. K. (2021). A survey of imbalanced data methodologies. arXiv.